Asymptotic Estimation, Interpolation and Extrapolation
Source:vignettes/articles/extrapolation.Rmd
extrapolation.RmdEstimation of diversity in entropart relies on classical assumptions that are recalled here. The observed data is a sample of a community (or several communities if data is a meta-community). All “reduced-bias estimator” are asymptotic estimators of the community diversity: if the sample size could be extended infinitely, diversity would tend to the diversity of the whole (asymptotic) community. In hyperdiverse ecosystems such as evergreen forests, the asymptotic community generally does not exist in the field because of environmental variations: increasing the size of the sample results in sampling in different communities. Thus, the asymptotic estimators of diversity correspond to theoretical asymptotic communities that do not necessarily exist. In other words, the asymptotic diversity is that of a community that would provide the observed sample.
Diversity is accumulated as a function of sample size. HCDT entropy (thus Hill numbers and phylodiversity) can be estimated at any sample size (Chao et al. 2014), by interpolation down from the actual sample size and by extrapolation up to infinite sample size, i.e. the asymptotic estimator. Alternatively, sample size may be replaced by sample coverage, by interpolation from arbitrary small sample coverages to that of the actual sample, and by extrapolation up to the asymptotic estimator whose sample coverage is 1.
Asymptotic estimation
If community data is a vector of probabilities, sample size is unknown so the only available estimation is that of the actual sample.
library("entropart")
data("Paracou618")
# 2 ha of tropical forest, distribution of probabilities
ParacouP <- Paracou618.MC$Ps
# Diversity of order 1, no reduced-bias estimator available
Diversity(ParacouP, q=1)## None
## 113.98Further estimation requires abundance vectors, i.e. the number of individuals per species. Then, the default estimator is the asymptotic one.
# 2 ha of tropical forest, distribution of abundances
ParacouN <- Paracou618.MC$Ns
# Diversity of order 1, best asymptotic estimator used.
Diversity(ParacouN, q=1)## UnveilJ
## 138.1078Several asymptotic estimators are available in the literature and implemented in entropart. For consistency, entropart uses the jackknife estimator of richness and the unveiled jackknife estimator for entropy. The advantage of these estimators is that they provide reliable estimations even though the sampling effort is low: then, the estimation variance increases but its bias remains acceptable because the order of the jackknife estimator is chosen according to the data. Poorly-sampled communities are estimated by a higher-order jackknife, resulting in higher estimation variance.
For well-sampled communities, i.e. in the domain of validity of the jacknife of order 1, the Chao1 estimator of richness and the Chao-Jost estimator of entropy are the best choices because they have the best mathematical support, but they will severely underestimate the diversity of poorly-sampled communities. They also are more computer-intensive.
# Estimation of richness relies on jackknife 2 (poor sampling)
Richness(ParacouN)## Jackknife 2
## 359
# Richness is underestimated by the Chao1 estimator
Richness(ParacouN, Correction="Chao1")## Chao1
## 314.9348
# Diversity of order 1 underestimated by the Chao-Jost estimator
Diversity(ParacouN, q=1, Correction="ChaoJost")## ChaoJost
## 133.2409Choosing the estimation level
Asymptotic estimation is not always the best choice, for example when comparing the diversity of poorly-sampled communities: a lower sample coverage can be chosen to limit the uncertainty of estimation.
# Actual sample coverage
Coverage(ParacouN)## ZhangHuang
## 0.9226675The estimation level may be a sample size or a sample coverage that is converted internally into a sample size.
# Diversity at half the sample size (interpolated)
Diversity(ParacouN, q=1, Level=round(sum(ParacouN)/2))## Interp
## 100.016
# Sample size corresponding to 90% coverage
Coverage2Size(ParacouN, SampleCoverage=0.9)## [1] 861
# Diversity at 90% sample coverage
Diversity(ParacouN, q=1, Level=0.9)## Interp
## 109.1493
# Equal to
Diversity(ParacouN, q=1, Level=Coverage2Size(ParacouN, SampleCoverage=0.9))## Interp
## 109.1493If the sample size is smaller than the actual sample, entropy is interpolated.
If it is higher, entropy must be extrapolated. For diversity orders equal to 0 (richness), 1 (Shannon) or 2 (Simpson), explicit, almost unbiased estimators are used. Continuity of the estimation of diversity around the actual sample size is guaranteed.
# Simpson diversity at levels from 0.9 to 1.1 times the sample size
Accumulation2 <- DivAC(ParacouN, q=2, n.seq=round(0.9*sum(ParacouN)):round(1.1*sum(ParacouN)))
autoplot(Accumulation2)## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## ℹ The deprecated feature was likely used in the entropart package.
## Please report the issue at <https://github.com/EricMarcon/entropart/issues/>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.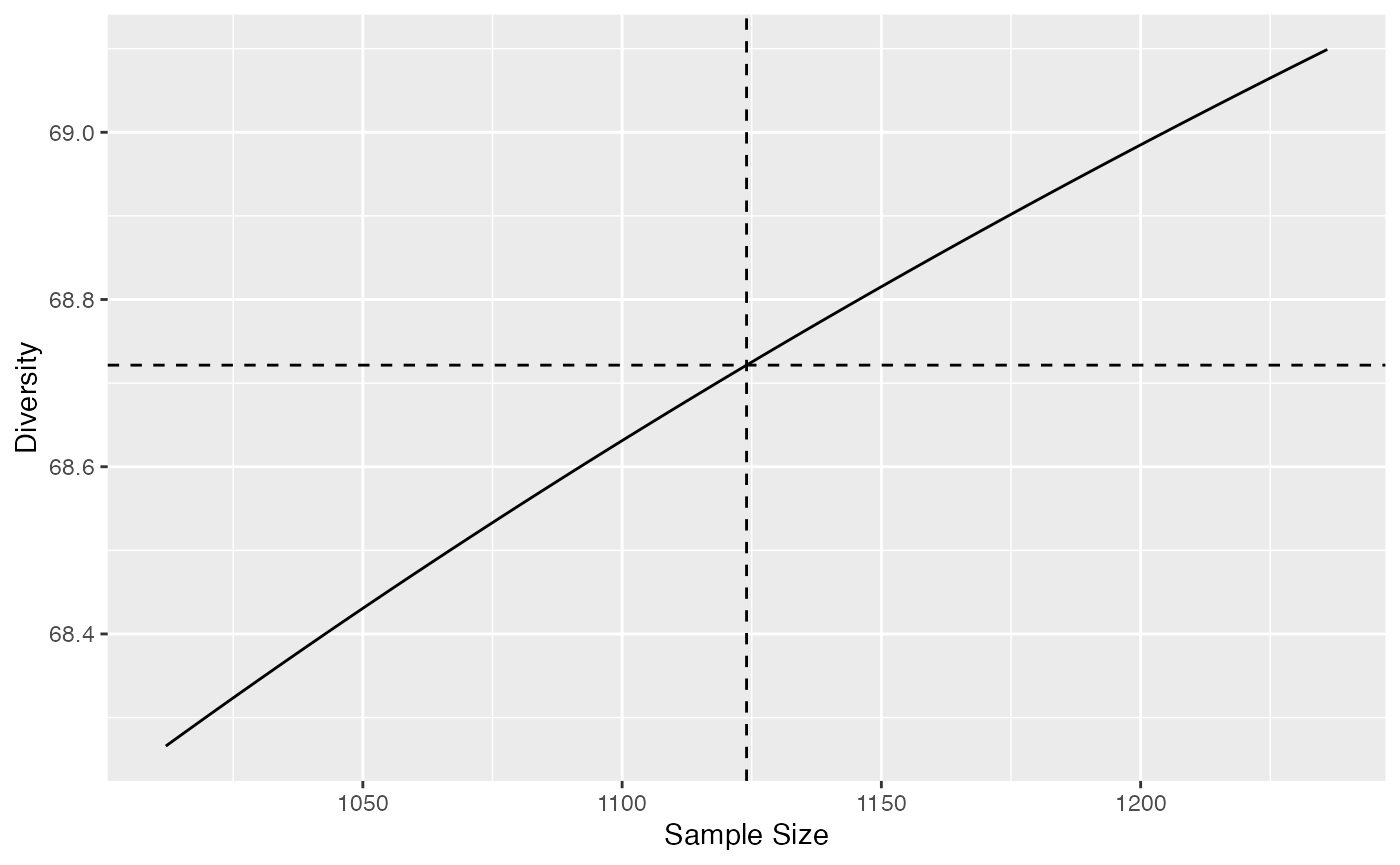
For non-integer orders, things get more complicated. In entropart, asymptotic entropy is estimated by the unveiled jackknife estimator and rarefied down to the actual sample size. There is no reason for it to correspond exactly to the observed entropy. The asymptotic richness is the less robust part of the estimation thus it is adjusted iteratively until the rarefied entropy equals the actual sample’s entropy, ensuring continuity between interpolation and extrapolation.
The default arguments of all functions apply this strategy, except for Simpson’s diversity () that is estimated directly without bias.
Diversity accumulation
Diversity Accumulation Curves (DAC) are a generalization of the well-known Species Accumulation Curves (SAC). They represent diversity as a function of sample size.
The DivAc() function allows to build them. A bootstrap
confidence interval can be calculated around the estimated DAC by
simulating random multinomial draws of the asymptotic distribution at
each sample size.
# Diversity at levels from 1 to twice the sample size
Accumulation <- DivAC(ParacouN, q=1, n.seq=seq_len(1.1*sum(ParacouN)), NumberOfSimulations = 1000)
autoplot(Accumulation)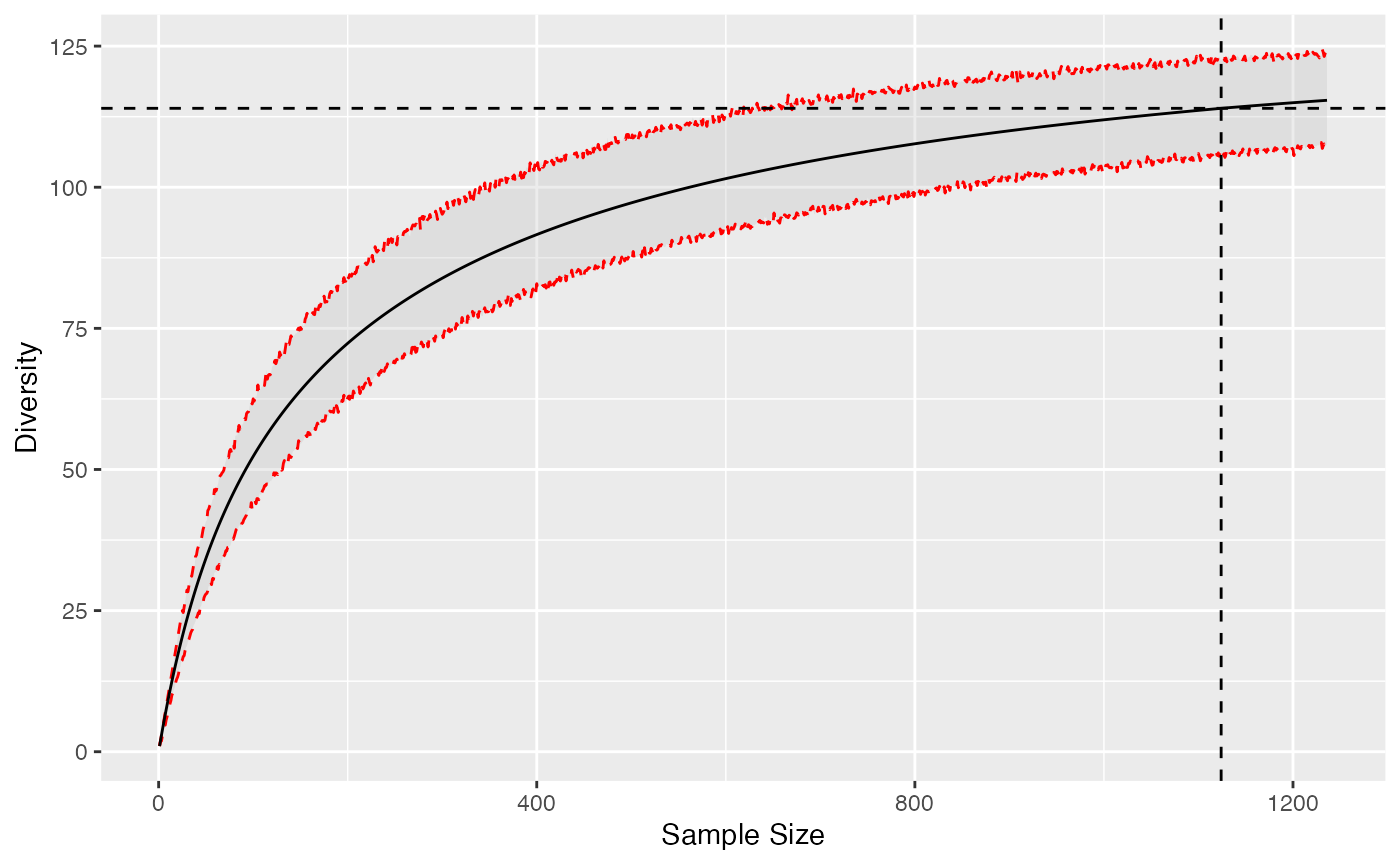
To ensure continuity of the DAC around the actual sample, the asymptotic diversity is estimated by unveiling the asymptotic distribution, choosing the number of species such that the rarefied diversity at the observed sample size is the observed diversity. This means that the extrapolated diversity at a high sample coverage will differ from the best asymptotic estimation, sometimes quite much if sampling level is poor.
# Extrapolation at 99.99% sample coverage
Diversity(ParacouN, q=1, Level=0.9999)## Best
## 128.3196
# Unveiled Jaccknife asymptotic estimator
Diversity(ParacouN, q=1)## UnveilJ
## 138.1078
# Chao-Jost estimator
Diversity(ParacouN, q=1, Correction="ChaoJost")## ChaoJost
## 133.2409Diversity profiles at a sampling level
Diversity profiles are usually asymptotic but they can be calculated at any coverage of sampling level.
# Diversity at levels from 1 to twice the sample size
Profile <- CommunityProfile(Diversity, ParacouN, Level=sum(ParacouN)*1.5)
autoplot(Profile)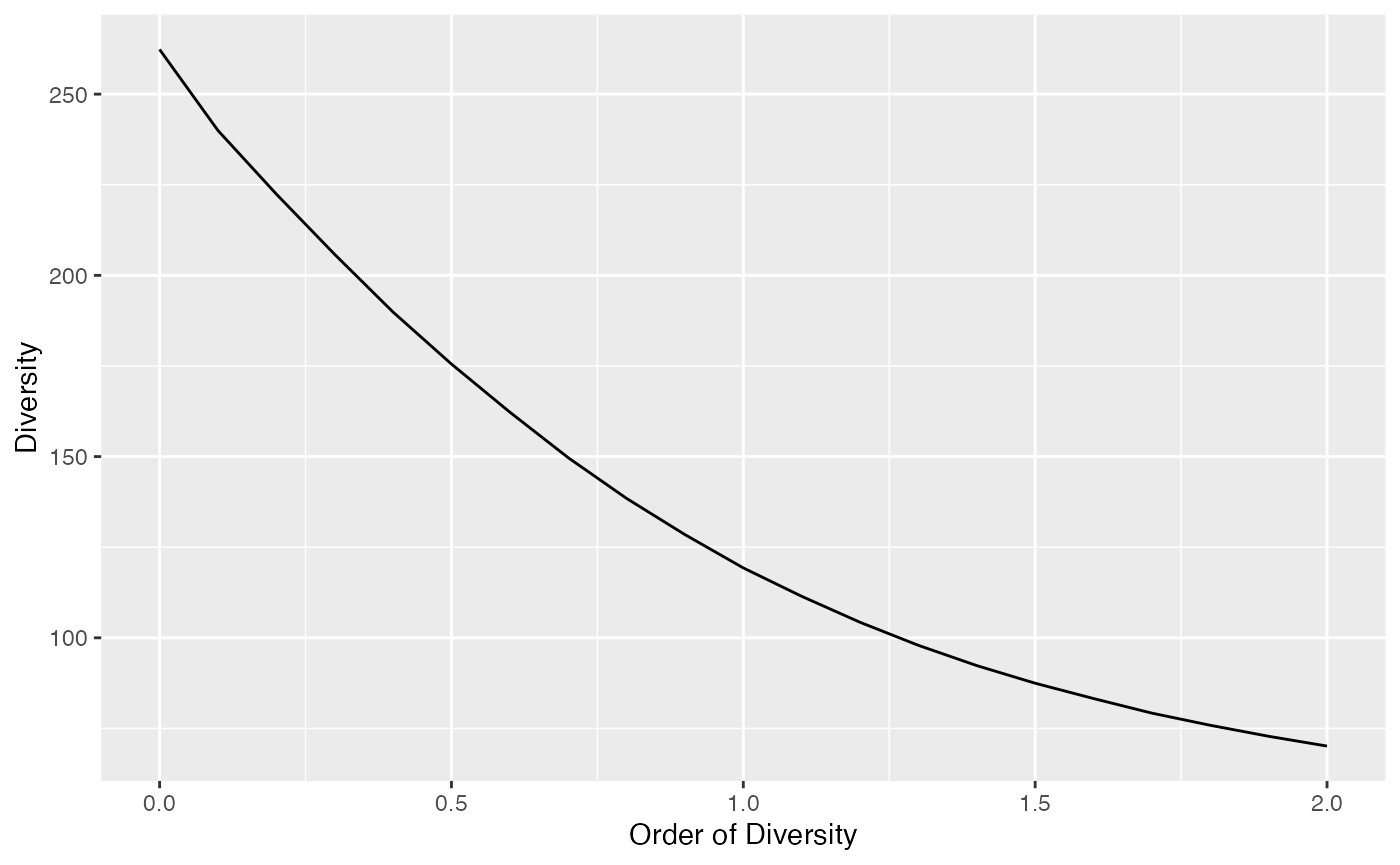
Extrapolated diversity is estimated at each order such that it is continuous at the observed sample size.
Differences with the iNEXT package
iNEXT (Hsieh, Ma, and Chao
2016) is designed primarily to interpolate or extrapolate
diversity of integer orders. Extrapolation of diversity of order 0
relies on the Chao1 estimator of richness and that of order 1 uses the
Chao-Jost estimator. In entropart, extrapolation relies on the
estimation of the asymptotic distribution of the community with
asymptotic richness such that the entropy of the asymptotic distribution
rarefied to the observed sample size equals the observed entropy of the
data. This approach allows consistent estimation of extrapolated
diversity at integer and non-integer orders, thus allowing consistent
diversity profiles without discontinuities at
and
.
The results of iNEXT can be obtained by forcing argument
PCorrection = "None" to avoid estimating the asymptotic
distribution and Correction="Chao1" for richness or
Correction="ChaoJost" for Shannon’s diversity.
library("iNEXT")
data(spider)
# Extrapolated diversity of an example dataset
estimateD(spider$Girdled, level=300)## Assemblage m Method Order.q SC qD qD.LCL qD.UCL
## 1 data 300 Extrapolation 0 0.9579518 33.317733 25.466844 41.168622
## 2 data 300 Extrapolation 1 0.9579518 12.869603 10.671626 15.067579
## 3 data 300 Extrapolation 2 0.9579518 7.983882 6.231075 9.736689
# Similar estimation by entropart
Diversity(spider$Girdled, q=0, Level=300, Correction="Chao1", PCorrection = "None")## Chao1
## 33.31773
Diversity(spider$Girdled, q=1, Level=300, Correction="ChaoJost", PCorrection = "None")## ChaoJost
## 12.8073
# Estimation at order 2 is explicit, with no optional choice
Diversity(spider$Girdled, q=2, Level=300)## Chao2014
## 7.983882
# Default estimation of entropart
Diversity(spider$Girdled, q=0, Level=300)## Best
## 32.09179
Diversity(spider$Girdled, q=1, Level=300)## Best
## 12.61092Small differences are due to different estimators of sample coverage:
entropart uses the more accurate ZhangHuang
estimator by default.
Last, confidence intervals of diversity accumulation assume normality in iNEXT: estimation variance is estimated by bootstrap and the confidence interval is defined as times the standard deviation. In entropart, confidence intervals are built directly from the quantiles of bootstrapped estimations.