4 Rédiger
R et RStudio permettent de rédiger efficacement des documents de tous formats, du simple bloc-note à la thèse, en passant par des diaporamas. Les outils pour le faire sont l’objet de ce chapitre, complété par la production de sites web (y compris un site personnel).
Deux procédés de production de documents sont disponibles :
- R Markdown avec les packages knitR et bookdown. C’est ma méthode classique, présentée ici en détail.
- Quarto, conçu pour être utilisé avec d’autres langages que R et dans d’autres environnements de travail que RStudio. Quarto est en développement actif mais ne permet pas encore de produire des documents avec la même qualité que R Markdown : par exemple, la ponctuation des documents en français n’est pas gérée correctement en PDF48, les tableaux ne peuvent pas inclure d’équations49 et la largeur des figures est incohérente dans les documents PDF formatés avec plusieurs colonnes50. L’usage de Quarto est bien documenté sur son site51 et n’est pas présenté ici.
4.1 Bloc-note Markdown (R Notebook)
Dans un fichier .R, le code doit toujours être commenté pour faciliter sa lecture.
Quand l’explication du code nécessite plusieurs lignes de commentaire par ligne ou bloc de code, il est temps d’inverser la logique et de placer le code dans un texte.
Le concept de programmation lettrée (literate programming) a été développé par Knuth (1984). Il s’agit de décrire les objectifs et les méthodes par du texte, dans lequel le code s’intègre.
L’outil le plus simple est le bloc-note Markdown (Menu “File > New File > R Notebook”). Le modèle de document contient son mode d’emploi.
Le langage qui permet de formater le texte est Markdown52, un langage de balisage simple à utiliser :
- Les paragraphes sont séparés par des sauts de ligne ;
- Le document est structuré par des titres : leur ligne commence par un nombre de
#correspondant à leur niveau ; - Les formats de caractères sont limités à l’essentiel : italique ou gras (texte entouré par une ou deux
*) ; - D’autres codes simples permettent tous les formatages utiles.
Ce langage est le pivot du logiciel pandoc53, dédié à la conversion de documents de formats différents.
Le package rmarkdown (Xie 2015) fait le lien entre R et Markdown, en s’appuyant sur l’interface de RStudio qui n’est pas indispensable mais simplifie énormément son utilisation. Le dialecte de Markdown utilisé par le package est appelé R Markdown. Sa syntaxe est résumée dans une antisèche54. Sa documentation complète est en ligne (Xie, Allaire, et Grolemund 2018).
Les équations sont écrites au format LaTeX55.
L’organisation la plus simple d’un document R Markdown est visible dans le modèle de bloc-note. Il commence par un en-tête au format YAML56:
---
title: "R Notebook"
output: html_notebook
---La première entrée est le titre, la seconde le format de sortie : plus précisément le nom de la fonction chargée de traiter le document.
Le document contient du texte formaté en Markdown et des bouts de code (code chunks) entourés par trois accents graves (la syntaxe markdown d’un bloc de code) et une description du langage, ici r.
Ces bouts de code sont traités par knitr qui transforme le résultat de l’exécution du code R en Markdown et l’intègre au texte du document.
Traiter un document R Markdown s’appelle le tricoter (knit). La chaîne de production est la suivante :
- knitr traite les bouts de code : calculs, production de figures ;
- rmarkdown intègre la production des bouts de code et texte pour produire un fichier Markdown standard ;
- pandoc (installé avec RStudio) convertit ce fichier au format HTML, LaTeX ou Word ;
- LaTeX produit un fichier PDF quand ce format est demandé.
RStudio permet de lancer le tricot par des boutons plutôt que par des commandes : dans la fenêtre source (celle du haut à gauche), un bouton “Knit” accompagne les documents R Markdown. Pour les bloc-notes R Markdown, il est remplacé par un bouton “Preview” avec les mêmes fonctions. Il peut être déroulé pour choisir le format de sortie : HTML, Word, PDF (en passant par LaTeX) et, pour les bloc-notes, une commande “Preview” qui affiche le document en HTML sans exécuter les bouts de code pour gagner du temps. Dès le premier tricot au format Word ou HTML, on remarquera que le bouton “Preview” disparaît.
Au final, l’utilisation de R Markdown combine plusieurs avantages :
- La simplicité de la rédaction : le texte brut est plus facile à lire et à formater qu’en LaTeX par exemple ;
- L’automatisation de la production : le formatage et la mise en page sont entièrement automatiques ;
- La reproductibilité : chaque document peut être autosuffisant accompagné de ses données. Relancer le tricotage régénère entièrement le document, y compris les calculs nécessaires et la production des figures.
Elle a aussi quelques inconvénients :
- Le formatage dépend de modèles, et developper de nouveaux modèles n’est pas simple ;
- Les erreurs de tricot sont parfois difficiles à corriger, notamment quand elles interviennent à l’étape de la compilation LaTeX ;
- La reproductibilité consomme du temps de calcul. Pour limiter ce problème, un système de cache permet de ne pas réévaluer tous les bouts de code R à chaque modification du texte. La production de gros documents peut aussi être déléguée à un système d’intégration continue (chapitre 6).
4.2 Modèles R Markdown
Des modèles de document plus élaborés que le bloc-note sont fournis par des packages, dont rmarkdown. Ils sont accessibles par le menu “File > New File > R Markdown…” (figure 4.1)).
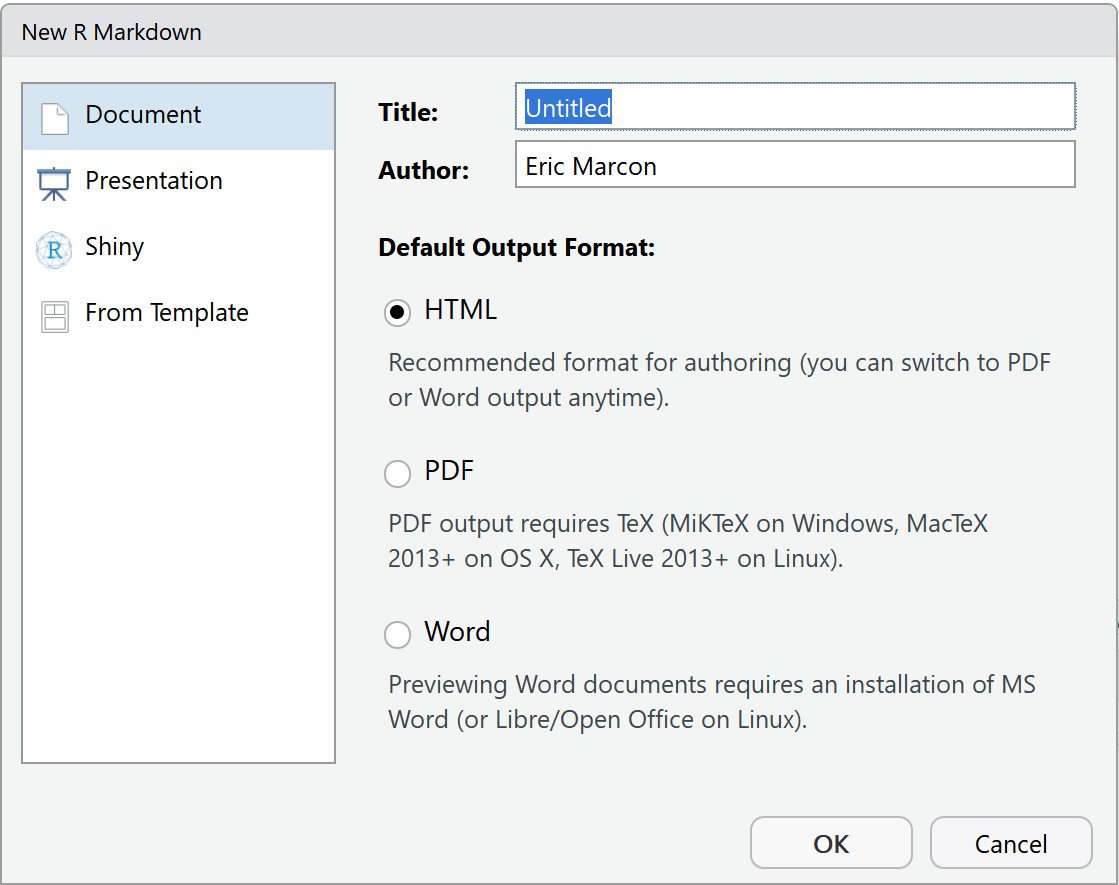
Figure 4.1: Nouveau document Markdown à partir d’un modèle.
Les modèles les plus simples sont Document et Presentation. Les informations à fournir sont le titre et le nom de l’auteur, et le format du document attendu (qui pourra être modifié plus tard). Ces modèles créent un seul fichier dont l’enregistrement ne sera obligatoire qu’au moment de tricoter.
La syntaxe est la même que celle du bloc-note. Dans l’entête, une entrée supplémentaire est utilisée pour la date, qui peut être calculée par R à chaque tricot :
date: "|r format(Sys.Date(), '%d/%m/%Y')|"Remplacer les barres verticales | de l’exemple ci-dessus par des guillemets inversés : ce document étant écrit avec R Markdown, la date serait calculée et affichée à la place du code si les guillemets inversés étaient utilisés directement.
Le code R en ligne (par opposition aux bouts de code) peut être utilisé partout dans un document R Markdown, y compris dans l’entête pour l’affichage de la date.
Il commence par un guillemet inversé suivi de r et se termine par un autre guillemet inversé.
Les documents peuvent être tricotés au format HTML, PDF (via LaTeX) ou Word. L’entête du fichier R Markdown est réécrit quand le tricot est lancé par le bouton de RStudio qui place en premier le format de sortie utilisé et l’ajoute si nécessaire.
Les présentations peuvent être tricotées dans deux formats HTML, ioslide57 ou Slidy58, au format Beamer (PDF)59 ou en Powerpoint60.
Le niveau 2 de plan (##) marque le changement de diapositive.
Du code supplémentaire, présenté dans les documentations des formats HTML, permet d’utiliser des fonctionnalités spécifiques.
Ces modèles sont simples mais assez peu utiles : le bloc-note R est plus facile à utiliser que le modèle de document pour des documents minimalistes. Des modèles plus élaborés sont disponibles.
4.3 Articles avec bookdown
R Markdown ne permet pas de rédiger un article scientifique. La bibliographie ne pose pas de problème parce qu’elle est gérée par pandoc pour les documents HTML ou Word et sous-traitée à LaTeX pour les documents PDF. Les équations, figures et tableaux sont numérotés par LaTeX mais pas en HTML. Les références croisées (les renvois à un numéro de figure par exemple) ne sont pas supportés. Enfin, les légendes de figures ou tableaux ne supportent que du texte brut, sans aucun formatage.
bookdown comble ces manques. Le package a été conçu pour la rédaction d’ouvrages comportant plusieurs chapitres mais peut être utilisé pour des articles.
Le package memoiR fournit les modèles présentés ici. Il doit être installé.
4.3.1 Ecrire
Les principales caractéristiques de Markdown sont résumées ici. Une formation rapide et plus complète est proposée par RStudio61.
Le texte est écrit sans aucun autre formatage que les les retours à la ligne. Un simple retour à la ligne n’a aucun effet sur le document produit : il permet de séparer les phrases pour simplifier le suivi du code source par git.
Un saut de ligne marque un changement de paragraphe.
Les différents niveaux de plan sont désignés par le nombre de croisillons correspondant en début de ligne : # pour un titre de niveau 1, ## pour un titre de niveau 2, etc.
Un espace sépare les croisillons et le texte du titre.
Les liste à puces sont marquées par un tiret (suivi d’un espace) en début de ligne. Un saut de ligne est nécessaire avant le début de la liste mais les éléments de la liste sont séparés par un simple retour à la ligne. Les listes indentées sont créées en insérant 4 espaces avant le tiret de début de ligne. Enfin, les listes numérotées sont créées de la même façon en remplaçant les tirets par des nombres, dont la valeur n’a pas d’importance.
Dans le texte, les parties en italique sont entourées par une étoile ou un tiret bas (*italique*), alors que deux étoiles marquent le gras.
4.3.1.1 Code R
Le code R est inclus dans des bouts de code (code chunks) créés facilement en cliquant sur le bouton “Insert a new code chunk” au-dessus de la fenêtre du code source dans RStudio. Ils commencent et se terminent par trois guillemets inversés sur une nouvelle ligne. Ces bouts de code peuvent contenir du code R mais aussi Python par exemple : le type de code est indiqué dans l’entête sur la première ligne, avant le nom du bout de code, puis une liste d’options séparées par des virgules, par exemple :
```{r cars, echo=TRUE}
```Le nom et les options sont facultatifs : l’entête minimal est {r}.
Les options les plus utiles sont :
-
echopour afficher (=TRUE) ou cacher (=FALSE) le code ; -
message=FALSEpour cacher les messages d’ouverture de certains packages ; -
warning=FALSEpour cacher les avertissements.
Les options par défaut sont déclarées dans le bout de code nommé “Options” au début du document Markdown, dans la fonction opts_chunk$set().
L’option include=FALSE supprime tout affichage lié au bout de code.
Dans un document tel qu’un article scientifique, qui n’affiche pas son code, elle doit être utilisée pour tous les bouts de code sauf ceux qui produisent les figures.
4.3.1.2 Figures
plot(pressure)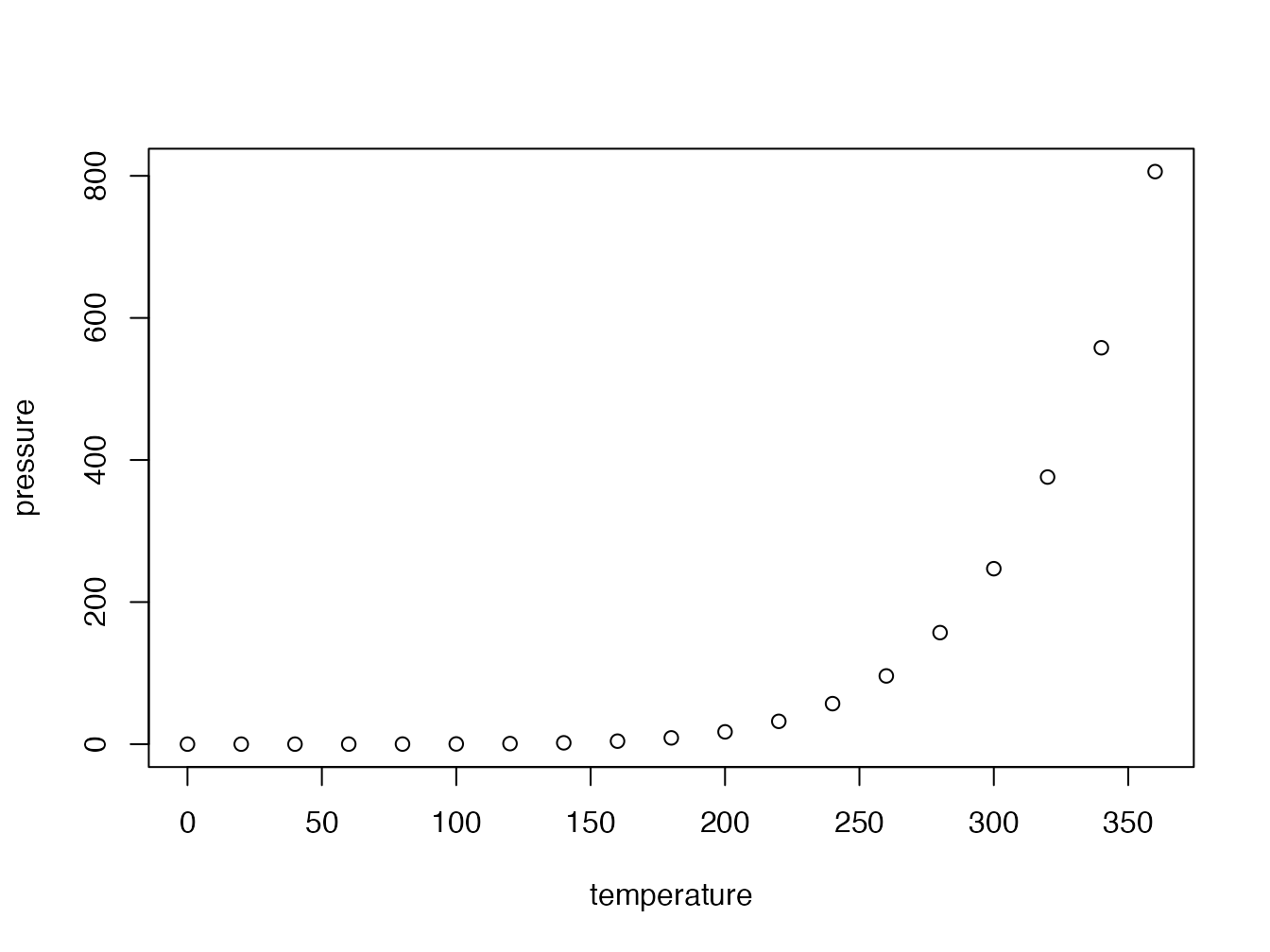
Figure 4.2: Titre de la figure
Les figures peuvent être créées par le code R (figure 4.2).
Avec Bookdown, une étiquette est associée à chaque figure : son nom est fig:xxx où xxx est le nom du bout de code R.
Les renvois se font avec la commande \@ref(fig:xxx).
L’entête du bout de code de la figure 4.2 est :
```{r pressure, fig.cap="Titre de la figure"}
```Il contient au minimum le nom de la figure et sa légende.
Si la légende est longue, l’entête est peu lisible.
De plus, la légende est limitée à du texte simple.
Pour des légendes plus élaborées, il est possible de déclarer la légende dans un paragraphe séparé qui commence par le texte (ref:NomFigure).
La figure 4.3 bénéficie d’une légende améliorée.
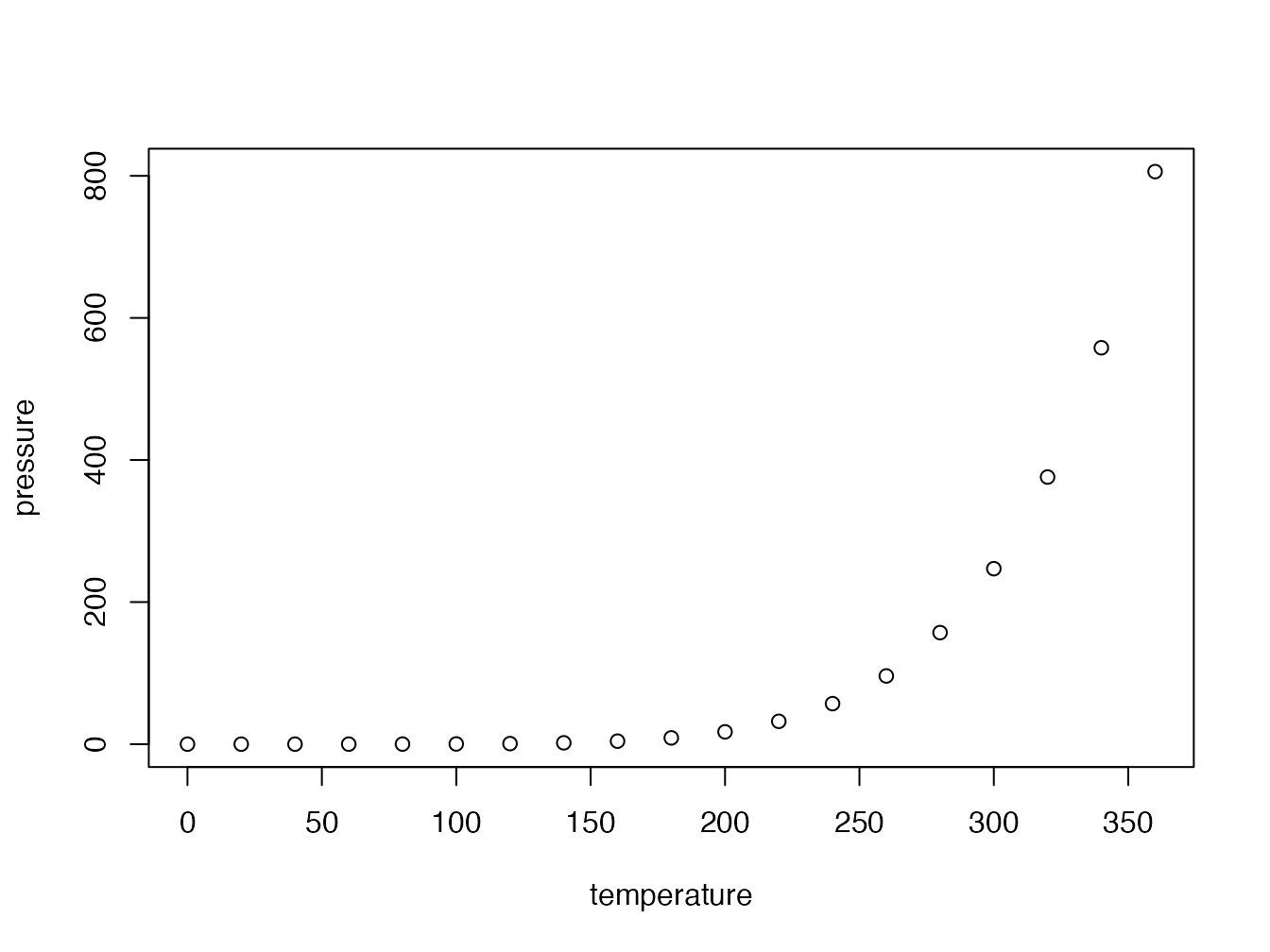
Figure 4.3: Titre avec italique, maths (\(\sqrt\pi\)) et renvoi vers la figure 4.2
Le texte de fig.cap, “Titre de la figure” précédemment, est remplacé par (ref:pressure) à l’intérieur des guillemets qui sont conservés et la légende est saisie dans un paragraphe commençant par (ref:pressure) suivi d’un espace.
Les légendes sont limitées à un paragraphe unique.
Si une table des figures est utilisée (option lof: true dans l’entête), une légende courte est nécessaire en plus de la légende complète.
Elle est déclarée dans fig.scap.
Les figures qui ne sont pas créées par R mais proviennent de fichiers sont intégrées dans un bout de code par la fonction include_graphics() dont l’argument est le fichier contenant l’image à afficher.
Placer systématiquement ces fichiers dans le dossier images pour une bonne organisation.
4.3.1.3 Tableaux
Les séparateurs horizontaux - et verticaux | permettent de dessiner un tableau selon la syntaxe de Markdown, mais ce n’est pas la meilleure méthode.
Les tableaux peuvent aussi être produits par du code R.
Le contenu du tableau est dans un dataframe.
La fonction kbl du package kableExtra prépare le tableau pour l’affichage et passe le résultat à la fonction kable_styling pour le formatage final.
library("tidyverse")
mes_iris <- head(iris)
names(mes_iris) <- c(
"Longueur sépales ($l_s$)",
"Largeur",
"Longueur pétales",
"Largeur",
"Espèce"
)
kableExtra::kbl(
mes_iris,
caption = "Tableau créé par kable",
booktabs = TRUE,
escape = FALSE
) %>%
kableExtra::kable_styling(
bootstrap_options = "striped",
full_width = FALSE
)| Longueur sépales (\(l_s\)) | Largeur | Longueur pétales | Largeur | Espèce |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
La légende est précisée par l’argument caption et le référencement est possible parce que le tableau reçoit une étiquette dont le nom est tab: suivi du nom du bout de code (tableau 4.1).
Comme pour les figures, une légende améliorée peut être écrite dans un paragraphe séparé.
Une légende courte pour une éventuelle liste des tableaux (option lot: true dans l’entête) est déclarée dans l’argument caption.short de kbl().
Utiliser systématiquement l’argument booktabs = TRUE pour que l’épaisseur des lignes de séparation soit optimale en LaTeX.
Comme le tableau contient des mathématiques (dans le nom de la première colonne), l’option escape = FALSE est nécessaire.
L’option de style bootstrap_options = "striped" fournit des tableaux plus lisibles en HTML.
Enfin, l’option full_width = FALSE permet d’ajuster la largeur du tableau à son contenu au lieu d’occuper toute la largeur disponible.
Le package flextable permet de réaliser des tableaux plus élaborés, comme dans l’exemple suivant qui affiche en couleur les longs sépales.
library("flextable")
# Rappel du jeu de données initial iris
iris %>%
# Premières lignes
head() %>%
# Création d'un objet flextable
flextable() %>%
# Titre des colonnes
set_header_labels(
Sepal.Length = "Longueur sépales",
Sepal.Width = "Largeur",
Petal.Length = "Longueur pétales",
Petal.Width = "Largeur",
Species = "Espèce"
) %>%
# Sélection des longs sépales (>5) et affichage en rouge
color(~Sepal.Length > 5, ~Sepal.Length, color = "red")Longueur sépales |
Largeur |
Longueur pétales |
Largeur |
Espèce |
|---|---|---|---|---|
5.1 |
3.5 |
1.4 |
0.2 |
setosa |
4.9 |
3.0 |
1.4 |
0.2 |
setosa |
4.7 |
3.2 |
1.3 |
0.2 |
setosa |
4.6 |
3.1 |
1.5 |
0.2 |
setosa |
5.0 |
3.6 |
1.4 |
0.2 |
setosa |
5.4 |
3.9 |
1.7 |
0.4 |
setosa |
La documentation du package62 est disponible en ligne, ainsi qu’une galerie63.
flextable ne supporte pas la numérotation des légendes hormis dans les documents Word. Cette limite est rédhibitoire.
4.3.1.4 Maths
Les équations au format LaTeX peuvent être insérées en ligne, comme \(A=\pi r^2\) (code : $A=\pi r^2$) ou isolées (les $ sont doublés) comme \[e^{i \pi} = -1.\]
Elles peuvent être numérotées : voir équation (4.1), en utilisant l’environnement \equation.
\[\begin{equation} A = \pi r^2. \tag{4.1} \end{equation}\]
L’équation numérotée est créée par le code suivant :
\begin{equation}
A = \pi r^2.
(\#eq:disque)
\end{equation}4.3.1.5 Références croisées
Les figures et tableaux ont une étiquette générée automatiquement, identique au nom du bout de code préfixé par fig: et tab:.
Pour les équations, l’étiquette est ajoutée manuellement par le code (\#eq:xxx) avant la fin de l’équation.
Les sections peuvent recevoir une étiquette en terminant leur titre par {#yyy}.
Les sections reçoivent par défaut une étiquette implicite64 correspondant à leur texte, en minuscules, où les caractères spéciaux sont remplacés par des tirets.
Les étiquettes implicites sont instables (elles changent avec le titre de la section) et difficiles à prévoir : c’est pourquoi il est conseillé d’ajouter une étiquette explicite à chaque section faisant l’objet d’un renvoi.
C’est le cas des chapitres, pour lesquels le nom du fichier HMTL produit est identique à l’étiquette.
Les étiquettes de chapitres doivent respecter les règles de nomenclature des fichiers en ne contenant pas de caractères spéciaux.
Des signets peuvent aussi être placés librement dans le texte avec la commande (ref:zzz).
Dans tous les cas, l’appel à la référence est fait par la commande \@ref(ref:zzz).
4.3.1.6 Bibliographie
Les références bibliographiques au format BibTeX doivent être incluses dans le fichier .bib déclaré dans l’entête du document Markdown.
bibliography: references.bibCe fichier peut être créé et maintenu à jour par Zotero installé avec l’extension Better BibTeX (voir section 1.6). Il suffit pour cela de créer une collection Zotero correspondant au projet et d’y glisser les références pertinentes. Utiliser ensuite le menu contextuel “Exporter la collection…” et sélectionner :
- Format : “Better BibTeX” pour les articles et présentations ou “Better BibLaTeX” pour les mémoires, selon que la bibliographie est gérée par BibTeX et natbib ou biber et BibLaTeX pour la production de documents PDF.
- Cocher la case “Garder à jour” pour que toute modification dans Zotero soit exportée automatiquement.
- Cliquer sur “OK” puis choisir le nom du fichier (
references.bib) et son emplacement (le dossier du projet R).
Les références peuvent être appelées dans le texte, entre parenthèses par le code [@Reference], ou dans le texte, en supprimant les crochets.
La bibliographie est traitée par pandoc lors de la production de documents Word ou HTML. Le style bibliographique peut être précisé, en ajoutant la ligne
csl:nom_du_fichier.csldans l’entête du document et en copiant le fichier de style .csl dans le dossier du projet. Plus d’un millier de styles sont disponibles65.
Pour les documents PDF, la bibliographie est gérée par LaTeX.
Pour préparer la soumission d’un manuscrit à une revue, il faudra ouvrir le fichier .tex intermédiaire produit par pandoc et copier le contenu de l’environnement {document} dans le modèle proposé par la revue, qui se chargera du formatage.
4.3.1.7 Langues
Les langues sont à déclarer dans l’entête des document produits par les modèles de memoiR.
La langue principale du document modifie le nom de certains éléments, comme la table des matières. Les langues supplémentaires permettent la rédaction de documents multilingues.
Les champs de l’entête sont :
lang: fr-FR
otherlangs: [en-US, it]Le changement de langue dans le document est géré en LaTeX mais pas en HTML en insérant sur une nouvelle ligne la commande suivante :
\selectlanguage{english}La langue en cours n’a d’effet que dans les sorties LaTeX : un espace est ajouté devant les ponctuations doubles en Français, la taille des espaces est plus grande en début de phrase en Anglais, etc.
La commande \selectlanguage est simplement ignorée en HTML.
Les noms de langues sont différents dans l’entête (codes IETF) et dans le texte (nom de la langue). La correspondance et la liste complète des langues se trouve dans le tableau 3 de la documentation du package polyglossia66.
Le formatage en HTML de la ponctuation des documents en français est possible par l’intermédiaire d’un filtre déclaré à pandoc 67.
Le fichier fr-nbsp.lua doit être copié dans le répertoire du projet à partir de son dépôt GitHub et éclaré dans l’entête du document Markdown.
output:
pandoc_args:
- --lua-filter=fr-nbsp.luaLe filtre formate toute la ponctuation du document, quelle que soit sa langue : il ne doit donc être utilisé que pour les documents entièrement en français.
4.3.2 Modèle Simple Article
Le modèle Simple Article de memoiR produit un document HTML simple avec une table des matières flottante (voir l’exemple68). D’autres formats HTML sont disponibles : voir la gallerie69 du package. Le format PDF est proche du modèle article de LaTeX (exemple70).
Le modèle contient sa propre documentation.
4.3.2.1 Créer
Utiliser le menu “File > New File > R Markdown…” puis sélectionner “From template” (figure 4.1). La liste des modèles disponible et le package qui les propose est alors affichée.
Sélectionner le modèle Simple Article du package memoiR, choisir le nom du projet (“Name :”, qui sera le nom du dossier dans lequel il sera créé, et son dossier parent (“Location :”).
Dans l’organisation proposée en section 1.2.4, le dossier parent est %LOCALAPPDATA%\ProjetsR.
Le nom du projet ne doit contenir aucun caractère spécial (accent, espace…) pour assurer sa portabilité sur tous les systèmes d’exploitation (Windows, Linux, MacOS).
Les modèles élaborés créent un dossier avec de nombreux fichiers (bibliographie, styles, modèle LaTeX…), contrairement aux modèles simples qui créent seulement un fichier.
Quand un dossier est créé, par exemple par le modèle Simple Article, il faut en faire un projet RStudio : dans le menu des projets (en haut à droite de la fenêtre de RStudio), utiliser le menu “New Project…” puis “Existing Directory” et sélectionner le dossier qui vient d’être créé.
4.3.2.2 Ecrire
Les instructions pour utiliser le modèle sont contenues dans le texte fourni par défaut.
4.3.2.3 Tricoter
Le document peut être tricoté en plusieurs formats :
- html_document2 est le format HTML pour lequel le modèle a été conçu : un bloc-note avec une table des matières flottante ;
- gitbook est un format HTML alternatif, utilisé normalement pour les ouvrages ;
- downcute est un format HTML proposé par le package rmdformats ;
- pdf_book produit un document PDF suivant le modèle LaTeX article, couramment utilisé directement en LaTeX ;
- word_document2 crée un ficher Word.
4.3.2.4 Mettre en ligne
Le package memoiR simplifie la mise en ligne des documents produits.
La fonction build_gitignore() crée un fichier .gitignore pour le contrôle de source qui doit être activé (voir section 3.1.1).
La fonction build_readme() crée un fichier README.md nécessaire à GitHub.
Il contient le titre du projet, son résumé et des liens vers les versions HTML et PDF des documents produits.
Le projet doit être lié à un dépôt GitHub (section 3.2).
Deux stratégies de publications sont possible.
Dans la première, les documents sont tricotés localement et placés dans le dossier docs, qui sera le support des pages GitHub.
Dans la seconde, les documents sont tricotés par GitHub Actions à chaque fois que des modifications sont poussées sur le dépôt : on parle d’intégration continue (section 6).
La stratégie de production locale est traitée ici ; l’intégration continue le sera dans la section 6.3.1.
La fonction build_githubpages() place tous les documents tricotés (HTML et PDF) dans le dossier docs, avec une copie du fichier README.md.
De cette façon, il est possible d’activer les pages GitHub du projet (sur le dossier docs de la branche master).
Le fichier README.md sera la page d’accueil du site web produit.
En pratique, on tricote au format HTML pendant toute la phase de rédaction, parce que la production est très rapide.
Quand le document est stabilisé, il faut le tricoter au format HTML et au format PDF.
Enfin, l’exécution de build_githubpages() place tous les fichiers produits dans docs.
Il reste à pousser le dépôt sur GitHub et activer les pages GitHub.
4.3.3 Autres modèles
Le modèle Stylish Article de memoiR est destiné à la production d’articles PDF pour l’autoarchivage (typiquement, le dépôt sur HAL) bien formatés, au format A4 en double colonne71.
Le format HTML est le même que celui du modèle Simple Article.
Le package rticles a pour ambition de fournir des modèles pour toutes les revues scientifiques qui acceptent une soumission d’articles en LaTeX.
Il propose donc des modèles Markdown qui produisent des fichiers PDF conformes aux exigences des revues et la possibilité de récupérer le fichier .tex intermédiaire (pandoc produit un fichier .tex transmis au compilateur LaTeX).
Le package ne permet pas de tricot HTML parce qu’il utilise la syntaxe LaTeX dans le document R Markdown au lieu d’utiliser bookdown pour gérer les références bibliographique et les références croisées.
Il n’est pas possible d’échanger directement du contenu R Markdown standard avec des documents écrits pour rticles, ce qui limite beaucoup l’intérêt du package.
4.4 Présentation Beamer
Le modèle Beamer Presentation de memoiR permet de créer des présentations au format HTML et PDF (beamer) simultanément, comme le montre l’exemple72.
La démarche est identique à celle des articles du même package.
Les niveaux de titre permettent de séparer les parties de la présentation (#) et les diapositives (##).
Deux formats sont disponibles en HTML : ioslides73 et Slidy74.
Quelques spécificités dans le code permettent d’affiner la présentation des diapositives, pour un affichage sur deux colonnes par exemple : elles sont documentées dans le modèle.
4.5 memoir
Le modèle Memoir du package memoiR est destiné aux documents longs, qui présentent une différence importante avec les documents précédents : un document long est composé de plusieurs chapitres, chacun placé dans son fichier .Rmd.
Le format HTML est gitbook75, le standard de la lecture en ligne de documents de ce type. Le format PDF est dérivé du modèle LaTeX memoir76, optimisé aussi pour les documents longs.
Ce document a été écrit avec ce modèle.
4.5.1 Créer
La création d’un projet d’ouvrage est identique à celle présentée plus haut : le modèle est : Memoir. Le dossier créé doit être transformé en projet.
Exécuter build_git() et build_readme(), activer le contrôle de source et pousser le projet sur GitHub, de la même façon que pour un article (section 4.3.2.4).
Chaque chapitre de l’ouvrage est un fichier Rmd, dont le nom commence normalement par son numéro (ex. : 01-intro.Rmd).
Tous les fichiers Rmd présents dans le dossier du projet sont en réalité traités comme des chapitres, triés par ordre de nom de fichier, dont ceux fournis par le modèle (démarrage et syntaxe) qui doivent être supprimés à l’exception de 99-references.Rmd qui contient la bibliographie, placée à la fin.
Le fichier index.Rmd est particulier : il contient l’entête du document et le premier chapitre.
4.5.2 Ecrire
Le premier chapitre est placé dans l’avant-propos de l’ouvrage imprimé : il ne doit pas être numéroté (d’où le code {-} à côté du titre) dans la version HTML.
Il se termine obligatoirement par la commande LaTeX \mainmatter qui marque le début du corps de l’ouvrage.
Les niveaux de plan commencent par # pour les chapitres (un seul par fichier), ## pour les sections, etc.
4.5.3 Tricoter
La compilation au format PDF est faite par XeLaTeX, qui doit être installé.
Pendant la rédaction, il est fortement conseillé de ne créer que le fichier HTML, ce qui est beaucoup plus rapide qu’une compilation LaTeX. Chaque chapitre peut être visualisé très rapidement en cliquant sur le bouton “Knit” au-dessus de la fenêtre de source. Le livre entier est créé en cliquant sur le bouton “Build Book” de la fenêtre Build de RStudio. La liste déroulante du bouton permet de créer tous les documents ou de se limiter à un format.
Les fichiers produits sont placés directement dans le dossier docs, qui sera utilisé par les pages GitHub pour permettre la lecture en ligne et le téléchargement du PDF.
La page d’accueil du site web est créée par bookdown à partir du fichier index.Rmd : le fichier README.md n’est pas dupliqué dans docs.
4.5.4 Finitions
La mise en page est assurée de façon totalement automatique par pandoc (en HTML) et LaTeX (en PDF).
Il est souvent utile d’aider LaTeX à résoudre quelques dépassements de marge dus à de trop grandes contraintes de mise en page : pour la lisibilité optimale, les colonnes sont étroites, mais le code (texte formaté entre deux apostrophes inversées) n’autorise pas la césure.
Si une ligne de texte dépasse dans la marge de droite dans le document PDF, la solution consiste à ajouter manuellement le code \break à l’emplacement désiré pour le retour à la ligne dans le document R Markdown.
La commande n’a aucun effet sur le document HTML mais force la césure en LaTeX.
Pour couper du texte formaté (entre astérisques pour l’italique ou plus fréquemment entre apostrophes inversées pour du code), il faut terminer le formatage avant \break et le recommencer après.
Exemple, pour forcer le retour à la ligne avant fichier.Rmd :
Le fichier `/chemin/`\break`fichier.Rmd`En HTML, un espace sera ajouté entre les deux portions de code.
Les bouts de code R sont formatés automatiquement par knitr quand l’option tidy=TRUE leur est appliquée.
Le comportement par défaut est indiqué dans les options de knitr, dans un bout de code au début du fichier index.Rmd :
# knitr options
knitr::opts_chunk$set(
cache = TRUE, warning = FALSE, echo = TRUE,
fig.env = 'SCfigure', fig.asp = .75,
fig.align = 'center', out.width = '80%',
tidy = TRUE,
tidy.opts = list(blank = FALSE, width.cutoff = 55),
size = "scriptsize",
knitr.graphics.auto_pdf = TRUE
)La largeur maximale d’une ligne de code formaté est ici de 55 caractères, optimal pour le modèle.
Il arrive que le formatage automatique ne fonctionne pas parce que knitr ne parvient pas à trouver une coupure de ligne respectant toutes les contraintes, ce qui provoque un dépassement de marge dans le code.
Dans ce cas, formater manuellement le bout de code en lui ajoutant l’option tidy=FALSE.
Les blocs de code littéral, délimités par trois apostrophes inversées, doivent être formatés manuellement, en évitant toute ligne de plus de 55 caractères.
4.5.5 Site gitbook
Le site web contenant le document gitbook doit être paramétré dans _output.yml pour que :
- le titre du document apparaisse en haut de la table des matières ;
- une indication de l’usage de GitHub et bookdown soit affichée en bas de la table des matières ;
- un bouton GitHub dans la barre de titre permette d’ouvrir le dépôt du projet ;
- un autre bouton permette de télécharger le document PDF.
Le fichier _output.yml de ce document est le suivant :
bookdown::gitbook:
css: style.css
config:
sharing:
github: yes
facebook: false
twitter: false
toc:
before: |
<li><a href="./">Travailler avec R</a></li>
after: |
<li>
<a href="https://github.com/EricMarcon/travailleR" target="blank">
Hébergé sur GitHub, publié par bookdown
</a>
</li>
download: pdfLa section sharing: gère les boutons de la barre de titre.
Par défaut, les liens vers Facebook et Twitter sont activés mais celui vers GitHub ne l’est pas.
Pour qu’il fonctionne, le dépôt GitHub doit être déclaré dans l’entête du fichier index.rmd :
github-repo: EricMarcon/travailleRLa section toc: contient deux portions de code HTML dans lesquelles le titre du document et le lien vers son dépôt GitHub doivent être adaptés au projet.
Enfin, la section download: liste les formats de documents téléchargeables et permet d’afficher un bouton de téléchargement dans la barre de titre.
4.5.6 Intégration continue
La construction d’un ouvrage prend du temps, surtout s’il contient des calculs. Elle doit être lancée au format gitbook et au format PDF. En production, elle peut être confiée à GitHub (chapitre 6.3.1.1).
4.5.7 Google Analytics
Le suivi de l’audience de l’ouvrage peut être confié à Google Analytics. Pour cela, il faut créer un compte et ajouter une propriété Google Analytics, c’est-à-dire un site web, puis un flux de données, ici un flux web77.
Google Analytics fournit un script de configuration nommé gtag.js à placer à la racine du dossier du projet.
Enfin, déclarer le script dans l’entête des pages web en ajoutant une instruction dans _output.yml, dans sa première section.
bookdown::gitbook:
includes:
in_header: gtag.js4.6 Site web R Markdown
Un site web constitué de pages écrites avec R Markdown (sans les fonctionnalités de bookdown) et un menu peut être créé très simplement, avec un résultat de bonne facture78.
4.6.1 Modèle
Dans RStudio, dans le menu des projets en haut à droite, cliquer sur “New Project…” puis “New Directory” puis “Simple R Markdown website”. Saisir le nom du projet, sélectionner le dossier dans lequel le projet sera créé en cliquant sur “Browse” et enfin cliquer sur “Create Project”.
Le site par défaut contient deux pages : index, la page d’accueil, et about, la page “A propos”.
Le fichier _site.yml contient le nom du site et le contenu de sa barre de navigation : un titre et le fichier correspondant.
D’autres pages seront ajoutées en créant de nouveaux fichiers .Rmd et en les ajoutant au fichier _site.yml.
4.6.2 Améliorations
Le modèle de site peut facilement être amélioré en complétant _site.yml :
- en ajoutant une icône GitHub dans la barre de navigation pour renvoyer vers le code source du site ;
- en choisissant la méthode de tricot des pages, pour utiliser bookdown au lieu de rmarkdown ;
- en plaçant les fichiers du site dans le dossier
docset ainsi séparer le code et la production.
Le fichier _site.yml complété est le suivant :
name: "my-website"
navbar:
title: "My Website"
left:
- text: "Home"
href: index.html
- text: "About"
href: about.html
right:
- icon: fa-github
href: https://github.com/rstudio/rmarkdown
output_dir: "docs"
output:
bookdown::html_document2:
theme: sandstone
highlight: tango
toc: true
toc_float: yesL’icône de GitHub fait partie de la collection Font Awesome dont toutes les icônes gratuites79 sont utilisables avec la même syntaxe : “fa-nom”.
Le lien correspondant à l’icône doit être celui du dépôt GitHub du site web.
La syntaxe de la section output est la même que celle des documents vus plus haut.
Elle s’applique à toutes les pages (dont l’entête YAML est réduite au minimum).
Les thèmes disponibles sont ceux de rmarkdown80.
L’option highlight indique la façon dont le code R éventuellement affiché sera formaté.
Enfin, la table des matières est flottante, ce qui signifie que sa position s’ajuste quand la fenêtre défile.
4.6.3 Contôle de source
Le projet doit être placé sous contrôle de source et poussé sur GitHub (chapitre 3).
Le fichier .gitignore est le suivant :
# R
.Rbuildignore
.RData
.Rhistory
.Rprofile
.Rproj.user
# Web Site
/_site/
/*_cache/
/*_files/Activer les pages GitHub (section 3.7) sur le dossier docs pour héberger le site.
Ajouter un fichier vide nommé .nojekyll dans docs pour que les pages GitHub ne tentent pas de reformater le site.
On peut utiliser le terminal de RStudio pour exécuter :
touch docs/.nojekyll4.7 Site web personnel : blogdown
Pour créer une page web personnelle, Hugo est un générateur de site statique capable de produire des pages HTML à partir de code Markdown. Les sites statiques ont l’avantage, en comparaison aux sites dynamiques gérés par un système de gestion de contenu (CMS, par exemple : Wordpress, Joomla, SPIP), d’être portables sur n’importe quel serveur web sans support de base de données ni de code à exécuter côté le serveur (tel que PHP) et d’être très rapides puisque les pages sont créées une seule fois et non à chaque consultation. Un site Hugo peut être hébergé par exemple sur la page personnelle de tout utilisateur de GitHub dont l’adresse est de la forme “GitHubID.github.io”.
Hugo propose de nombreux thèmes, qui sont des modèles de structure de sites, donc le thème Academic, destiné aux chercheurs. Dans RStudio, le package blogdown est prévu pour produire facilement des pages web avec Hugo. Ces pages peuvent contenir du code R : elles sont très proches d’un article, vu plus haut, dont le contenu peut être facilement copié et collé. Nous utiliserons donc cette solution, pour un site comme celui proposé en exemple81.
La structure du site web est simple :
- une page d’accueil, contenant divers composants paramétrables comme la biographie de l’auteur, une sélection de publications, de billets de blogs ou d’autres éléments et un formulaire de contact ;
- des pages détaillant les divers éléments (publications, billets, etc.) écrites en R Markdown.
4.7.1 Installation des outils
La première étape consiste à installer le package blogdown dans R.
install.packages('blogdown') blogdown est capable d’installer Hugo sous Windows, macOS ou Linux.
blogdown::install_hugo()La documentation complète de blogdown est disponible82.
Les versions récentes de Hugo utilisent Go (le langage de programmation) pour installer leurs modules à la volée : ici le thème Academic est chargé depuis GitHub au moment de la création du site. Go doit donc être installé83.
4.7.2 Créer
La façon la plus simple consiste à créer un dépôt sur GitHub à partir du modèle. Sur la page du dépôt starter-academic84, cliquer sur le bouton “Use this template”, s’authentifier éventuellement sur GitHub, puis saisir le nom du dépôt qui contiendra le projet, par exemple “MySite”.
Le dépôt peut être celui du site principal de son compte GitHub (voir section 3.7), à l’adresse https://GitHubID.github.io85. Le nom à saisir est simplement “GitHubID.github.io” (GitHubID est le nom du compte GitHub).
Créer le dépôt. Copier l’adresse du dépôt en cliquant sur le bouton “Code” puis sur le bouton à droite de l’adresse (figure 4.4).
Figure 4.4: Copie de l’adresse d’un dépôt à cloner sur GitHub.
Dans RStudio, créer un nouveau projet à partir de GitHub : dans le menu des projets en haut à droite, cliquer sur “New Project…” puis “Version Control” puis “Git” puis coller l’adresse dans le champ “Repository URL” (figure 4.5). Sélectionner le dossier dans lequel le projet sera créé en cliquant sur “Browse” et enfin cliquer sur “Create Project”.
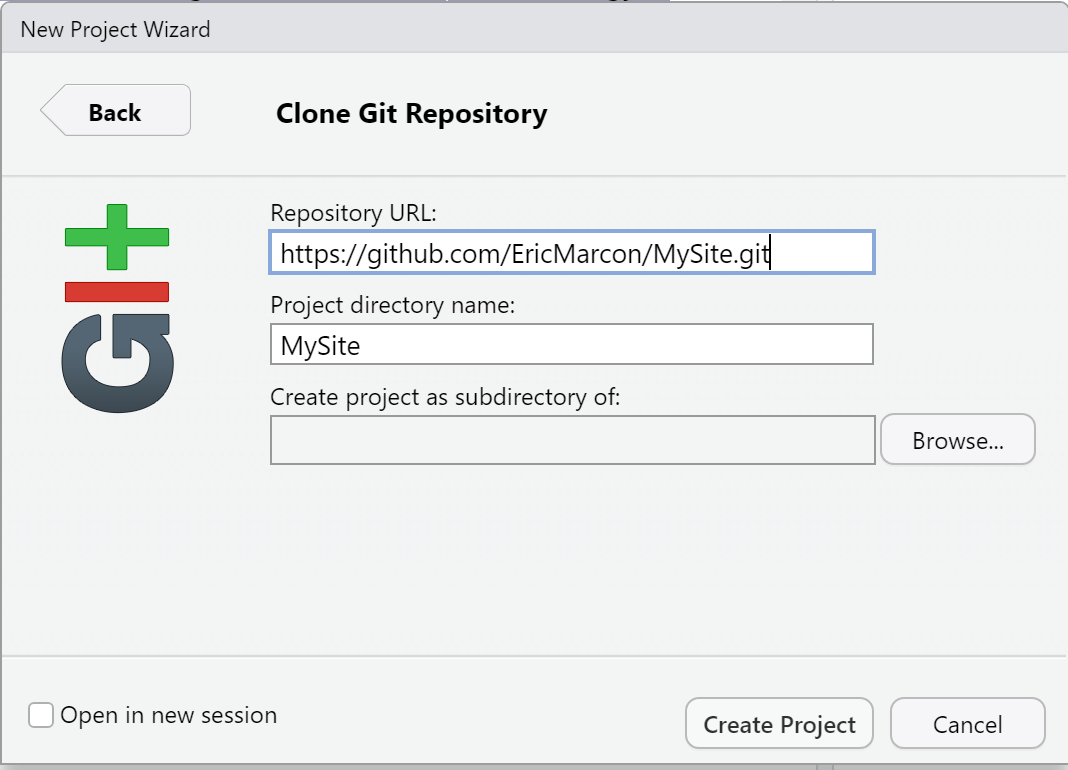
Figure 4.5: Collage de l’adresse du dépôt à cloner.
Le projet créé est une copie exacte du modèle, qui doit être personnalisée.
RStudio ajoute automatiquement à la fin du fichier .gitignore une ligne pour ignorer ses fichiers de travail (dossier .Rproj.user).
Ajouter une ligne de commentaire pour le signaler.
Le contenu de .gitignore doit être le suivant :
# R
.Rbuildignore
.RData
.Rhistory
.Rprofile
.Rproj.user
# Hugo
/resources/
/public/
# blogdown
/static/en/
/static/fr/
*.rmarkdown
_index.html
index.html
**/index_files/Un bug de blogdown nécessite de déplacer le fichier config.toml du dossier config/_default/ à la racine du projet.
Prendre en compte ces modification dans git en faisant un commit.
4.7.3 Construction du site
Exécuter
blogdown::build_site(build_rmd = TRUE)pour construire le site web, y compris ses futures pages R Markdown.
Pour afficher le site, exécuter :
blogdown:::serve_site()Il apparaît dans la fenêtre Viewer de RStudio, dont le bouton d’agrandissement permet l’affichage dans le navigateur internet par défaut du système.
Pour modifier le contenu du site, il est préférable d’arrêter le serveur web par la commande :
blogdown:::stop_server()Le site produit par blogdown se trouve dans le dossier public qui peut être copié directement sur un serveur web qui l’hébergera.
Une solution simple consiste à déclarer ce dossier comme racine des pages GitHub du projet
(section 3.7).
La méthode optimale consiste à utiliser l’intégration continue (voir section 6.3.2) pour le copier à la racine de la branche gh-pages qui sera déclarée comme emplacement du site sur GitHub.
4.7.4 Site multilingue
Si le site est multilingue, son contenu (dossier content) doit être copié dans un dossier correspondant à chaque langue.
Par exemple, le fichier content/authors/admin/_index.md qui contient les informations sur le propriétaire du site est remplacé par content/en/authors/admin/_index.md et content/fr/authors/admin/_index.md si le site supporte l’Anglais et le Français.
En pratique, créer un dossier en et un dossier fr dans content.
Déplacer tout le contenu de original de content dans en puis copier ce même contenu dans fr.
4.7.5 Paramétrer
Les fichiers de configuration du site sont bien documentés et offrent de nombreuses options. Les principales sont passées en revue ici pour une création rapide d’un site fonctionnel.
Le fichier config.toml contient les paramètres généraux du site.
Les lignes à mettre à jour sont celle du titre du site (le nom du propriétaire puisqu’il s’agit d’un site personnel) et son adresse publique.
Pour le site exemple :
title = "Eric Marcon"
baseurl = "https://EricMarcon.github.io/"Il contient aussi la ligne de sélection de la langue par défaut (“en” ou “fr” au choix) et celle qui permet de placer les fichiers produits par Hugo dans chaque dossier de langue (“true” obligatoirement pour un site multilingue) :
defaultContentLanguage = "fr"
defaultContentLanguageInSubdir = trueLe dossier config/_default/ contient les autres fichiers de configuration.
languages.toml contient les paramètres linguistiques et les traductions de menus.
Pour chaque langue, la version utilisée et le dossier de contenu sont précisés :
[en]
languageCode = "en-us"
contentDir = "content/en"
[fr]
languageCode = "fr-fr"
contentDir = "content/fr"Pour les langues additionnelles, le titre du site, les paramètres d’affichage des dates et la traduction des menus sont ajoutés.
Dans la section [fr] :
[fr]
languageCode = "fr-fr"
contentDir = "content/fr"
title = "Eric Marcon"
description = "Page personnelle d'Eric Marcon"
[fr.params]
description = ""
date_format = "02-Jan-2006"
time_format = "15:04"
[[fr.menu.main]]
name = "Accueil"
url = "#about"
weight = 20
(...)Ces lignes sont commentées dans le modèle et doivent dont être décommentées en retirant les # en têtes de lignes.
Les menus sont décrits plus bas.
params.toml décrit l’aspect du site.
Les options sont regroupées par sujet, par exemple “Theme” pour l’apparence générale.
Dans “Basic Info”, la ligne
site_type = "Person"sélectionne un site personnel. Il est possible d’utiliser Academic pour un site de projet scientifique ou un site d’unité, non documentés en détail ici. Les principales différences sont, pour un site collectif :
- la gestion des auteurs : dans le dossier
/contents/<langue>/authors, un seul dossieradminest utilisé pour un site personnel alors qu’un dossier par personne est nécessaire pour un site collectif ; - un composant décrit plus bas, qui permet de présenter les personnes, doit être activé.
La description du site dans la langue par défaut est saisie, à destination des moteurs de recherche :
description = "Eric Marcon's Homepage"Elle doit être traduite dans le fichier languages.toml, dans chaque langue.
Dans “Site Features”, nous sélectionnons la coloration du code R, l’activation du formatage des équations et l’avertissement légal pour l’utilisation des cookies.
highlight_languages = ["r"]
math = true
privacy_pack = trueLa ligne edit_page doit être mise à jour : remplacer le dépôt par défaut “https://github.com/gcushen/hugo-academic” par celui du site.
“Contact details” contient les informations pour contacter le propriétaire du site. Elles doivent être saisies.
“Regional Settings” contient les paramètres d’affichage de date pour la langue par défaut (ceux des autres langues sont dans languages.toml).
Ils n’ont normalement pas à être modifiés.
“Comments” permet d’activer les commentaires des visiteurs en bas de pages, avec Disqus ou Comment.io (un compte est nécessaire chez le fournisseur).
“Marketing” permet d’activer le suivi de fréquentation du site en saisissant simplement son identifiant Google Analytics (à créer avec un compte Google).
“Content Management System” contient la ligne netlify_cms dont la valeur doit être false si le site n’est pas hébergé par Netlify.
Enfin “Icon Pack Extensions” permet d’activer les icônes Academicons si nécessaire.
4.7.6 Ecrire
Utiliser la documentation en ligne86 en complément des informations principales détaillées ici. L’exemple utilisé ici est le site personnel de l’auteur87.
La méthode de travail consiste à progresser pas à pas en testant puis validant chaque étape :
- effectuer les modifications ;
- construire le site et vérifier le résultat :
blogdown:::serve_site(); - arrêter le site :
blogdown::stop_server(); - si le résultat n’est pas satisfaisant, recommencer ;
- valider les modifications (commit).
4.7.6.1 Page d’accueil
La page d’accueil du site est constituée par une suite d’éléments (widgets) qui se trouvent dans /contents/<langue>/home.
Chaque élément est décrit par un fichier markdown.
Le premier est index.md.
Il n’est normalement jamais modifié.
Son contenu est le suivant :
+++
# Homepage
type = "widget_page"
headless = true # Homepage is headless, other widget
pages are not.
+++Le fichier ne contient qu’un entête au format TOML, encadré par une ligne de +++.
Le type de composant (type) indique qu’il s’agit d’une page de composants, dans laquelle les autres composants du dossier trouveront leur place.
headless = true signifie que la page n’a pas d’en-tête.

Figure 4.6: Composant demo dans Academic.
Le composant demo.md (figure 4.6) est un composant de type “blank”, c’est-à-dire une page de texte libre : il sert ici à présenter le modèle Academic Kickstart et doit donc être désactivé.
L’entête contient ses informations de formatage (titre, nombre de colonnes, couleurs…) et le contenu de la page est écrit en markdown.
Les composants apparaissent par ordre croissant de poids (weight dans l’entête) : 15 marque le premier composant dans le modèle Academic.
Le composant peut être désactivé en supprimant son fichier ou en modifiant sa propriété active dans l’entête :
active = false # Activate this widget? true/false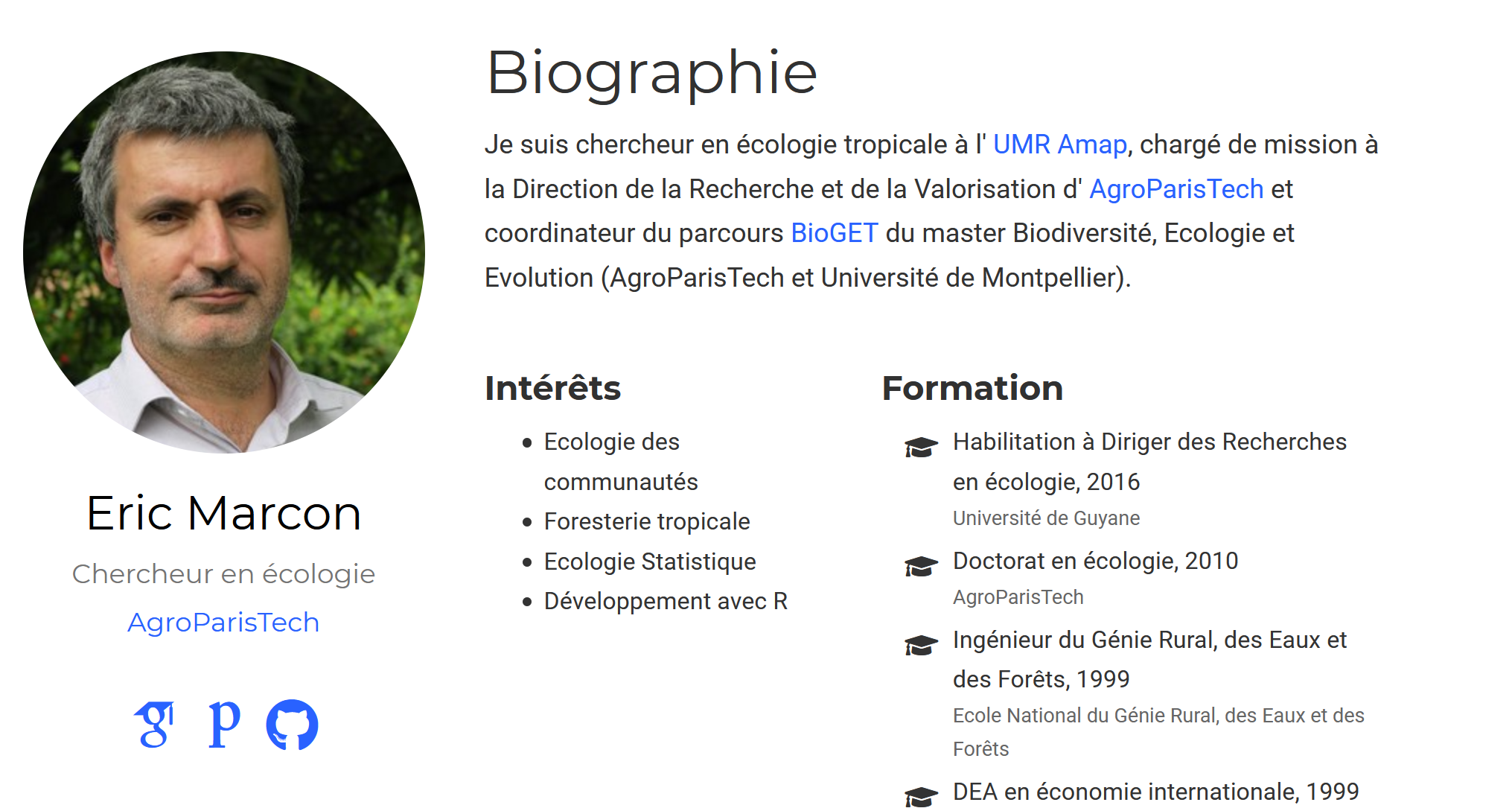
Figure 4.7: Composant about dans Academic.
Le composant suivant est about.md (figure 4.7).
Il présente le propriétaire du site.
Son titre doit être localisé.
Dans le dossier /content/fr/home, sa valeur sera :
title = "Biographie"L’auteur (author) doit correspondre à un dossier de /contents/<langue>/authors.
admin convient parfaitement pour un site personnel.
Academic permet de créer des sites d’équipes : dans cette configuration, un dossier par personne serait nécessaire.
L’image affichée par le composant est le fichier avatar.jpg placé dans ce dossier.
Limiter la taille du fichier pour la performance du site (moins d’un mégaoctet est une taille raisonnable), tout en assurant une taille minimale de quelques centaines de pixels de côté pour la qualité de l’affichage.
Le contenu du composant est lu dans le fichier _index.md du même dossier, qui contient toutes les informations sur l’auteur.
Son organisation est assez claire : modifier son contenu à partir de l’exemple fourni.
Si des icônes de type ai sont utilisées, activer le pack d’icône Academicons dans config/_default/params.toml.

Figure 4.8: Composant skills dans Academic.
Le composant talents (skills, figure 4.8) présente les compétences de l’auteur de façon graphique.
Une collection d’icônes est disponible, et des icônes nouvelles peuvent être ajoutées.
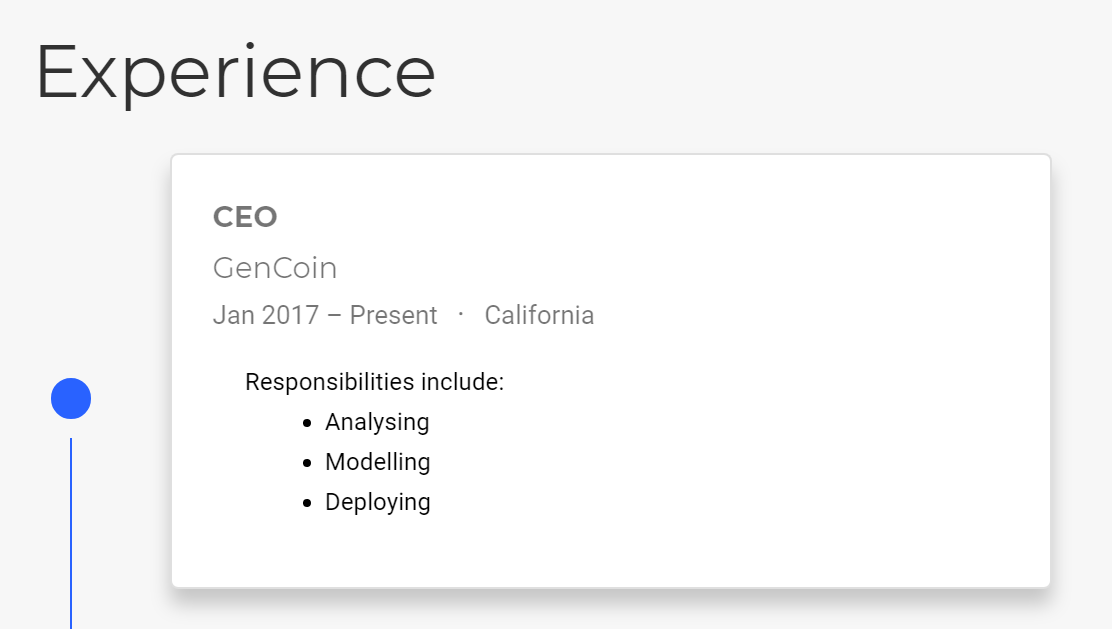
Figure 4.9: Composant experience dans Academic.
Le composant expérience (experience, figure 4.9) liste les expériences professionnelles.
Toutes les informations sont saisies dans son entête.
Le composant accomplishments présente les formations professionnelles et permet d’accéder à leurs certificats.
Le composant posts va chercher son contenu dans le dossier /contents/<langue>/post qui contient les billets de blog (voir plus bas).
Le fichier posts.md contient des options de mise en page dans son entête.
Le composant projects fonctionne de la même façon.
La différence entre les deux composants est leur mise en forme : posts est du type “pages”, qui affiche les éléments les plus récents, alors que projects est de type “portfolio”, qui affiche les éléments sélectionnés qui contiennent la description featured: true dans leur propre entête.
Il est possible de créer des composants de ces types librement, en spécifiant le dossier contenant les éléments dans “page-type”.
Exemple : créer un composant nommé software.md en renommant projects.md, modifier sa ligne page_type = "software" et créer un dossier /contents/<langue>/software pour y placer du contenu.
Les composants publications et featured sont de type “pages” et “portfolio” respectivement et prennent leur contenu dans le dossier publication.
Le composant tags présente un nuage de mots à partir des mots-clés déclarés dans tous les fichiers de contenu (billets de blog, publications…) sous la forme suivante dans leur entête :
tags = ["Mot Clé 1", "Autre Mot Clé"]Enfin, le composant contact permet d’afficher un formulaire de contact.
Il utilise les informations du fichier config/_default/params.toml dans sa partie commençant par :
############################
## Contact details
##Pour afficher une carte, entrer la latitude et la longitude de l’adresse dans la ligne coordinates.
Pour afficher un formulaire de messagerie, choisir le service formspree.io (email_form = 2 dans contact.md).
Pour activer le service de messagerie, il faudra construire le site web, s’envoyer un premier message en utilisant le formulaire et suivre les instructions de Formspree.
Le composant people est utilisé dans les sites collectifs pour présenter les membres.
Le composant slider permet d’afficher un carrousel (des éléments défilants) en haut de page.
Pour comprendre son fonctionnement, le plus simple consiste à l’activer.
4.7.6.3 Billets
Le site est alimenté par des billets de blog placés dans le dossier /contents/<langue>/post.
Il doivent être traduits et placés dans le dossier post de chaque langue pour être disponibles dans la langue correspondante.
L’exemple utilisé ici est un guide pour estimer correctement la densité d’une variable bornée88.
Son code est sur GitHub89.
Un billet est placé dans un dossier (/content/fr/post/densite) qui contient son code R Markdown et éventuellement des images, des données pour alimenter le code et d’autres éléments appelés par le code.
Hugo supporte des fichiers markdown natifs.
L’apport de blogdown relativement à un site Hugo natif est le support de R Markdown, donc la possibilité d’exécuter tout code R comme dans un bloc-note (dont le contenu peut être réutilisé sans modification).
Le fichier principal d’un billet est index.Rmd.
blogdown crée un fichier index.html pendant la construction du site : il peut être ignoré (dans .gitgnore) et supprimé à tout moment.
Si une image featured.png (optimale pour un schéma) ou featured.jpg (optimale pour un photo) est placée dans le dossier, elle sera utilisée comme vignette du billet.
index.Rmd comprend un entête au format yaml (entourée par des ---) ou toml (entourée par des +++) qui décrit son affichage :
---
title: "Titre du billet"
subtitle: "Sous-titre"
summary: "Résumé"
authors: []
tags: ["Mot Clé 1", "Autre Mot Clé"]
categories: []
date: 2020-04-17
featured: false
draft: false
# Featured image
# To use, add an image named `featured.jpg/png` to
# your page's folder.
# Focal points: Smart, Center, TopLeft, Top, TopRight,
# Left, Right, BottomLeft, Bottom, BottomRight.
image:
caption: ""
focal_point: ""
preview_only: false
bibliography: references.bib
---Les auteurs sont utilisés dans les sites collectifs.
Les tags permettent d’alimenter le composant nuage de mots s’il est activé dans la page d’accueil.
Les catégories permettent de rechercher des pages au contenu similaire (recherche par mot-clé sur le site).
L’option featured: true fait apparaître le billet dans les composants de type featured sur la page d’accueil.
L’option draft: true cache le billet.
Les éléments suivants précisent l’affichage de la vignette : légende et position.
L’option preview_only: true limite l’affichage aux miniatures (sur la page d’accueil), retirant donc l’image du billet lui-même.
Les éléments d’entête nécessaires au corps de texte R Markdown, comme le nom du fichier contenant les références bibliographiques, placé dans le même dossier, sont ajoutés.
Le corps du texte est celui d’un document R Markdown standard, avec du code R inclus. Un bout de code initial permet de fixer les options de R et charger les packages nécessaires.
En pratique, la façon la plus efficace de créer un nouveau billet est de copier le dossier complet d’un billet précédent, de le renommer et de modifier son contenu.
La commande blogdown::new_post() peut aussi être utilisée mais ne gère pas les langues multiples (et crée donc le billet dans le dossier /contents/post à moins de préciser l’argument subdir).
La reconstruction du site ne met par défaut pas à jour les pages basées sur un fichier .Rmd.
Pour le faire, il faut forcer la commande build_site().
blogdown::build_site(build_rmd = TRUE)
blogdown::serve_site()4.7.6.4 Publications
Les publications sont organisées comme les billets, mais placées dans le dossier /contents/<langue>/publications.
L’exemple utilisé est un article de revue90 avec son code91.
Un fichier cite.bib contenant la référence au format BibTeX est placé dans le dossier.
Le nom du dossier est de préférence celui de l’identifiant de la publication.
L’entête du fichier index.md (ici au format Markdown, mais .Rmd est possible si du code R est nécessaire) contient les mêmes informations que le fichier BibTeX, mais au format approprié (yaml), et les éléments propres à Academic (featured) :
---
title: "Evaluating the geographic concentration of |>
industries using distance-based methods"
authors: ["Eric Marcon", "Florence Puech"]
publication_types: ["2"]
abstract: "We propose (...)"
publication: "*Journal of Economic Geography*"
doi: "10.1093/jeg/lbg016"
date: 2003-10-01
featured: false
---Les types de publication sont :
- 0 = Uncategorized ;
- 1 = Conference paper ;
- 2 = Journal article ;
- 3 = Preprint / Working Paper ;
- 4 = Report ;
- 5 = Book ;
- 6 = Book section ;
- 7 = Thesis ;
- 8 = Patent.
Des boutons sont affichés en haut de la page de la publication en fonction des informations trouvées :
- PDF : si la ligne
urlest présente dans l’en-tête ; - Citation : si le fichier
cite.bibest présent dans le dossier ; - DOI : si la ligne
doiest présente dans l’en-tête.
Le corps de la publication contient un lien (au format HTML) vers le site Dimension qui fournit des informations bibliométriques. Ce lien peut être réutilisé très simplement, en remplaçant simplement le DOI du document :
<span class="__dimensions_badge_embed__"
data-doi="10.1093/jeg/lbg016"></span>
<script async src="https://badge.dimensions.ai/
badge.js" charset="utf-8"></script>Enfin, un fichier /contents/<langue>/publications/_index.Rmd permet de présenter la bibliographie complète.
Il est accessible à partir du composant publications de la page d’accueil qui affiche un lien “Plus de Publications”.
Le fichier exemple92 avec son code93 permet d’interroger Google Scholar pour obtenir le réseau de coauteurs, l’indice h et le nombre de citations annuelles de l’auteur. Il est réutilisable en modifiant simplement l’identifiant Google Scholar à la ligne 30.
En faisant exécuter le code régulièrement, par exemple par GitHub (voir ci-dessous), les statistiques affichées sont maintenues à jour sans intervention humaine.
4.7.6.5 Communications
Les communications sont organisées comme les publications, dans le dossier /contents/<langue>/talk.
L’exemple utilisé est une communication en Français, donc dans /contents/fr/talk94 avec son code95.
Une image peut être utilisée plus facilement que pour une publication.
L’entête contient des lignes particulières adaptées aux communications :
---
title: "Construction de l'estimateur de biodiversité |>
Chao1"
event: "Semaine des mathématiques 2020"
event_url: https://eduscol.education.fr/cid59178/|>
semaine-des-mathematiques.html
location: Université de Guyane
summary: []
abstract: |
Pour estimer le nombre d’espèces (richesse
spécifique) d’une communauté à partir d’un
échantillon, l’estimateur Chao1 est l’outil
le plus utilisé.
Sa construction est expliquée et son efficacité
est testée sur des données simulées.
# Talk start and end times.
# End time can optionally be hidden by
# prefixing the line with `#`.
date: "2020-03-11T11:00:00Z"
date_end: "2020-03-11T12:00:00Z"
all_day: false
# Schedule page publish date (NOT talk date).
publishDate: "2020-04-14"
# Is this a featured talk? (true/false)
featured: false
image:
caption: 'Produit scalaire des vecteurs $v_0$ |>
et $v_2$'
focal_point: Smart
url_code: "https://github.com/EricMarcon/Chao1"
url_pdf: "https://EricMarcon.github.io/Chao1/|>
Chao1.pdf"
url_slides: "https://EricMarcon.github.io/Chao1/|>
Chao1.html"
# Enable math on this page?
math: true
---Les liens (url_code par exemple) font apparaître des boutons qui permettent d’afficher respectivement le code source de la présentation, un fichier pdf et les diapositives en ligne.
4.7.6.6 Autres éléments
Il est possible d’ajouter librement des éléments supplémentaires sur le site :
- dans
/contents/<langue>/, créer un dossier dont le nom est le type d’éléments (exemple :recette) ; - ajouter des éléments dans ce dossier, chacun dans son propre dossier ;
- le fichier obligatoire est
index.mdouindex.Rmdavec un en-tête contenant possiblement tous les champs rencontrés dans les élémentspost,publicationettalk; - le fichier de vignette,
featured.pngoufeatured.jpg, est facultatif ; - tous les fichiers nécessaires au tricot (images, données) peuvent être ajoutés dans le même dossier ;
- dans
/contents/<langue>/home, ajouter un composant de la page d’accueil en copiant-collant un élément existant de type “pages” (commepublications) ou “portfolio” (commefeatured) et le paramétrer pour qu’il pointe sur le bon dossier (dans l’exemple :page-type=recette) et ajuster son apparence (nombre d’éléments par exemple) et sa position (poids) ; - ajouter éventuellement une entrée de menu pour pointer sur le composant, avec le même poids que le composant.
Les fichiers d’index peuvent porter l’extension .Rmd ou .md.
Dans le premier cas, ils seront traités par blogdown, qui supporte l’intégration de code R.
Dans l’autre cas, ils seront traités par Hugo, qui ne gère que le format markdown standard.
Les fichiers .md nécessitent moins de ressource et sont donc préférés quand ils suffisent.
4.7.7 Intégration continue
La construction du site web en production peut être confiée à GitHub (section 6.3.2), y compris sa mise à jour périodique si des pages du site traitent des données qui évoluent dans le temps.
4.7.8 Mises à jour
Le thème Academic est régulièrement mis à jour.
La version utilisée est indiquée dans le fichier go.mod.
Pour utiliser la dernière version officielle, exécuter dans la console R la commande suivante :
blogdown::hugo_cmd("mod get -u")Les fichiers go.mod et go.sum, qui contient les codes de hachage des fichiers du module, sont mis à jour.
Chaque changement de version peut nécessiter des adaptations du contenu du site, référencées dans la documentation en ligne du thème96.
Mettre Hugo à jour en même temps :
blogdown::update_hugo()4.8 Exportation de figures
Quand la production de documents avec R Markdown n’est pas possible, les figures issues de R doivent être exportées sous forme de fichiers pour être intégrés dans un autre processus d’écriture. Il est préférable de créer des scripts pour créer les figures de façon reproductible et au format optimal.
4.8.1 Formats vectoriels et raster
Les figures doivent en général être produites dans un format vectoriel :
- SVG pour la publication d’affiches ou de posters ;
- EMF (Extended Meta-File) pour Word ou la suite Microsoft Office qui ne supporte pas d’autres formats ;
- EPS (Encapsulated PostScript) ou PDF (Portable Document Format) pour LaTeX.
Les figures raster (composées d’un ensemble de points, comme les photographies) sont rares dans R.
La fonction image() utilisée pour afficher des cartes utilise par défaut des polygones plutôt que des points.
La figure 4.10 montre le résultat du code suivant :
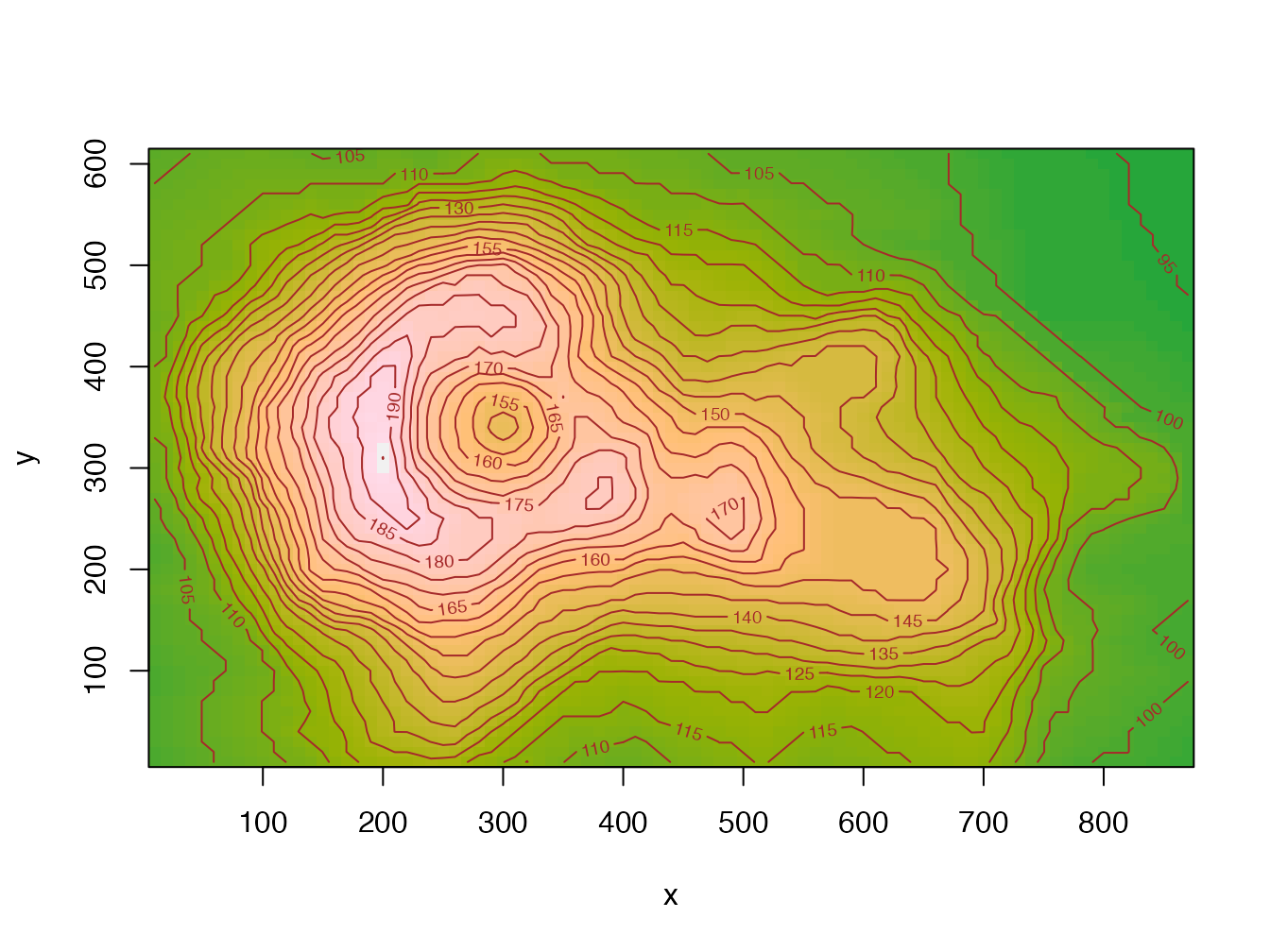
Figure 4.10: Courbes de niveau du volcan Maunga Whau, code fourni en exemple de l’aide de la fonction image().
Elle est composée d’un ensemble de rectangles colorés : il s’agit bien d’une image vectorielle.
Si nécessaire, des images peuvent être produites aux formats BMP (bitmap, sans compression), JPEG (compressées avec perte de qualité), PNG (compressées sans perte de qualité, avec transparence possible) ou Tiff (compressées ou non).
4.8.2 Fonctions
Les graphiques produits par ggplot() peuvent être sauvegardés dans un fichier par la fonction ggsave().
L’extension du nom du fichier définit son format.
Voir l’aide de la fonction pour plus de détails.
Les autres graphiques nécessitent une méthode différente.
La fonction postscript() produit un fichier EPS.
Le code R doit appeler la fonction pour créer le fichier, produire la figure, puis fermer le fichier, par exemple :
# Ouverture du fichier
postscript("Fig1.eps", width = 6, height = 4, horizontal = FALSE)
# Création de la figure
plot(cars)
# Fermeture du fichier
dev.off()## pdf
## 2La largeur et la hauteur (en pouces) d’un fichier vectoriel n’ont pas d’importance, mais leur rapport fixe l’aspect de la figure. La taille des textes est fixe : augmenter la taille de la figure revient donc à diminuer la taille relative des textes : procéder par essais successifs, en veillant à ce que les légendes restent lisibles à la taille finale de la figure.
L’argument horizontal fixe l’orientation de la figure de façon assez imprévisible : procéder par essais.
Les fonctions eps(), pdf(), bmp(), jpeg(), png() et tiff() fonctionnent de la même manière.
Se référer à l’aide des fonctions pour le choix des options (résolution, niveau de compression, etc.).
La fonction emf() est fournie par le package devEMF.
Les polices de caractères ne sont pas incluses dans les fichiers EPS ou PDF.
Si nécessaire, la fonction embedFonts() permet d’y remédier, à condition que GhostScript soit installé.
4.8.3 Package ragg
Le package ragg97 améliore la qualité des fichiers PNG, JPEG et TIFF.
Les fonctions optimisées sont agg_png(), agg_jpeg()et agg_tiff(). Leur usage est le même que celui des fonctions de grDevices.
Les documents R Markdown produisent des images au format PNG pour leur version HTML.
ragg améliore leur qualité : le package doit être installé et dev = "ragg_png" doit être ajoutée aux options de knitr.
Pour ce document, les options déclarées dans index.Rmd sont les suivantes :
# knitr options
knitr::opts_chunk$set(
cache = FALSE, # Cache chunk results
include = TRUE, # Show/Hide chunks
echo = TRUE, # Show/Hide code
warning = FALSE, # Show/Hide warnings
message = FALSE, # Show/Hide messages
# Figure alignment and size
fig.align = 'center', out.width = '80%', fig.asp = .75,
# Graphic devices (ragg_png is better than standard png)
dev = c("ragg_png", "pdf"),
# Code chunk format
tidy = FALSE, tidy.opts = list(blank = FALSE, width.cutoff = 60),
size = "scriptsize", knitr.graphics.auto_pdf = TRUE
)
options(width = 60)Enfin, ragg peut être utilisé comme moteur de rendu graphique par défaut dans RStudio à partir de la version 1.4 (Menu “Tools > Global Options > General > Graphics > Backend”).
4.9 Flux de travail
Un flux de travail (voir section 2.8) peut être intégré dans un document R Markdown à partir de la version 0.5 du package targets.
4.9.1 Déclaration du flux
Le flux est géré par des bouts de code de type targets.
Leur entête minimal est targets au lieu de {r}, et ils doivent être nommés.
Ces bouts de code permettent de créer le fichier _targets.R quand ils sont exécutés en mode non interactif, notamment pendant que le document est tricoté.
S’ils sont lancés en mode interactif, par exemple dans R Studio, leur code est exécuté.
L’option tar_interactive = FALSE dans leur entête permet de les tester sans tricoter tout le document.
Un ancien flux éventuel doit être supprimé avant d’écrire le nouveau :
Le premier bout de code, avec l’option tar_globals=TRUE, écrit les options globales du flux.
Pour créer le flux présenté en section 2.8, le code est simplement :
```{targets targets_global, tar_globals=TRUE}
# Packages
tar_option_set(packages = c("spatstat", "dbmss"))
```Les fonctions utilisées par les cibles sont déclarées dans ce type de bout de code : elles sont ajoutées à un fichier dans le dossier de travail _targets_r (différent du dossier _targets qui contient les fichiers de calcul des cibles).
4.9.2 Déclaration des cibles
Les cibles elles-mêmes sont déclarées dans des bouts de code dont le nom est celui de la variable de destination.
```{targets X, tar_simple=TRUE}
runifpoint(NbPoints)
```Chaque cible nécessite un bout de code construit de cette manière.
La valeur de la cible est la dernière valeur retournée, à la manière d’une fonction qui n’utiliserait pas return().
Pendant le tricot, ce code simplifié (tar_simple=TRUE) est transformé automatiquement en écriture de cible :
tar_target(X, {
runifpoint(NbPoints)
})La lecture du document est alourdie par cette syntaxe particulière : targets n’est pas utile pour des documents dont le code, rapide à exécuter, doit être affiché dans le texte. En revanche, si le code est long à exécuter et n’est pas affiché, son intérêt est considérable pour limiter le temps de calcul.
Les autres bouts de code nécessaires pour compléter le flux sont les suivants :
-
NbPoints:
tar_target(NbPoints, {
1000
})-
d:
tar_target(d, {
sum(pairdist(X)) / NbPoints / (NbPoints - 1)
})-
map:
tar_target(map, {
autoplot(as.wmppp(X))
})4.9.3 Exécution du flux
Pour lancer le calcul des cibles, un bout de code standard ({r}) doit appeler tar_make() :
tar_make()## + NbPoints dispatched
## ✔ NbPoints completed [658ms, 53 B]
## + X dispatched
## ✔ X completed [1ms, 11.06 kB]
## + d dispatched
## ✔ d completed [3ms, 55 B]
## + map dispatched
## ✔ map completed [11ms, 187.83 kB]
## ✔ ended pipeline [834ms, 4 completed, 0 skipped]tar_visnetwork() permet de vérifier que le flux est correct avant de l’exécuter.
Au moment de la production finale du document, l’option include=FALSE peut être ajoutée à l’entête de ce bout de code pour qu’il ne produise aucun affichage.
4.9.4 Utilisation des résultats
Les bouts de code qui utilisent les valeurs des cibles doivent les lire avec tar_read() :
tar_read(map)
4.9.5 Contrôle de source
Les fichiers de targets doivent être inclus au contrôle de source. De cette façon, les calculs effectués localement ne seront pas répétés par GitHub Actions (chapitre 6) et la construction du document sera rapide.